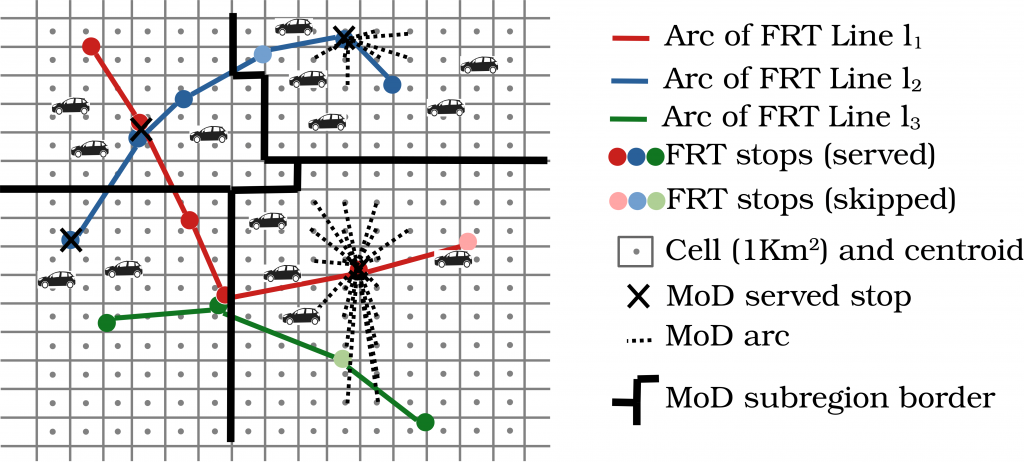
Cryptography: what are the random numbers for?
Hervé Debar, Télécom SudParis – Institut Mines-Télécom and Olivier Levillain, Télécom SudParis – Institut Mines-Télécom
The original purpose of cryptography is to allow two parties (traditionally referred to as Alice and Bob) to exchange messages without another party (traditionally known as Eve) being able to read them. Alice and Bob will therefore agree on a method to exchange each message, M, in an encrypted form, C. Eve can observe the medium through which the encrypted message (or ciphertext) C is sent, but she cannot retrieve the information exchanged without knowing the necessary secret information, called the key.
This is a very old exercise, since we speak, for example, of the ‘Julius Caesar Cipher’. However, it has become very important in recent years, due to the increasing need to exchange information. Cryptography has therefore become an essential part of our everyday lives. Besides the exchange of messages, cryptographic mechanisms are used in many everyday objects to identify and authenticate users and their transactions. We find these mechanisms in phones, for example, to encrypt and authenticate communication between the telephone and radio antennas, or in car keys, and bank cards.
The internet has also popularized the ‘padlock’ in browsers to indicate that the communication between the browser and the server are protected by cryptographic mechanisms. To function correctly, these mechanisms require the use of random numbers, the quality (or more precisely, the unpredictability) thereof contributes to the security of the protocols.
Cryptographic algorithms
To transform a message M into an encrypted message C, by means of an algorithm A, keys are used. In so-called symmetric algorithms, we speak of secret keys (Ks), which are shared and kept secret by Alice and Bob. In symmetric algorithms, there are public (KPu) and private (KPr) key pairs. For each user, KPu is known to all, whereas KPr must be kept safe by its owner. Algorithm A is also public, which means that the secrecy of communication relies solely on the secrecy of the keys (secret or private).
Sometimes, the message M being transmitted is not important in itself, and the purpose of encrypting said message M is only to verify that the correspondent can decrypt it. This proof of possession of Ks or KPr can be used in some authentication schemes. In this case, it is important never to use the same message M more than once, since this would allow Eve to find out information pertaining to the keys. Therefore, it is necessary to generate a random message NA, which will change each time that Alice and Bob want to communicate.
The best known and probably most widely used example of this mechanism is the Diffie-Helman algorithm. This algorithm allows a browser (Alice) and a website (Bob) to obtain an identical secret key K, different for each connection, by having exchanged their respective KPu beforehand. This process is performed, for example, when connecting to a retail website. This allows the browser and the website to exchange encrypted messages with a key that is destroyed at the end of each session. This means that there is no need to keep it (allowing for ease of use and security, since there is less chance of losing the key). It also means that not much traffic will be encrypted with the same key, which makes cryptanalysis attacks more difficult than if the same key were always used.
Generating random numbers
To ensure Eve is unable obtain the secret key, it is very important that she cannot guess the message NA. In practice, this message is often a large random number used in the calculations required by the chosen algorithm.
Initially, generating random variables was used for a lot of simulation work. To obtain relevant results, it is important not to repeat the simulation with the same parameters, but to repeat the simulation with different parameters hundreds or even thousands of times. The aim is to generate numbers that respect certain statistical properties, and that do not allow the sequence of numbers to be differentiated from a sequence that would be obtained by rolling dice, for example.
To generate a random number NA that can be used in these simulations, so-called pseudo-random generators are normally used, which apply a reprocessing algorithm to an initial value, known as the ‘seed’. These pseudo-random generators aim to produce a sequence of numbers that resembles a random sequence, according to these statistical criteria. However, using the same seed twice will result in obtaining the same sequence twice.
The pseudo-random generator algorithm is usually public. If an attacker is able to guess the seed, he will be able to generate the random sequence and thus obtain the random numbers used by the cryptographic algorithms. In the specific case of cryptography, the attacker does not necessarily even need to know the exact value of the seed. If they are able to guess a set of values, this is enough to quickly calculate all possible keys and to crack the encryption.
In the 2000s, programmers used seeds that could be easily guessed, that were based on time, for example, making systems vulnerable. Since then, to avoid being able to guess the seed (or a set of values for the seed), operating systems rely on a mixture of the physical elements of the system (e.g. processing temperature, bus connections, etc.). These physical elements are impossible for an attacker to observe, and vary frequently, and therefore provide a good seed source for pseudo-random generators.
What about vulnerabilities?
Although the field is now well understood, random number generators are still sometimes subject to vulnerabilities. For example, between 2017 and 2021, cybersecurity researchers found 53 such vulnerabilities (CWE-338). This represents only a small number of software flaws (less than 1 in 1000). Several of these flaws, however, are of a high or critical level, meaning they can be used quite easily by attackers and are widespread.
A prime example in 2010 was Sony’s error on the PS3 software signature system. In this case, the reuse of a random variable for two different signatures allowed an attacker to find the manufacturer’s private key: it then became possible to install any software on the console, including pirated software and malware.
Between 2017 and 2021, flaws have also affected physical components, such as Intel Xeon processors, Broadcom chips used for communications and Qualcom SnapDragon processors embedded in mobile phones. These flaws affect the quality of random number generation. For example, CVE-2018-5871 and CVE-2018-11290 relate to a seed generator whose periodicity is too short, i.e. that repeats the same sequence of seeds quickly. These flaws have been fixed and only affect certain functions of the hardware, which limits the risk.
The quality of random number generation is therefore a security issue. Operating systems running on newer processors (less than 10 years old) have random number generation mechanisms that are hardware-based. This generally ensures a good quality of the latter and thus the proper functioning of cryptographic algorithms, even if occasional vulnerabilities may arise. On the other hand, the difficulty is especially prominent in the case of connected objects, whose hardware capacities do not allow the implementation of random generators as powerful as those available on computers and smartphones, and which often prove to be more vulnerable.
Hervé Debar, Director of Research and Doctoral Training, Deputy Director, Télécom SudParis – Institut Mines-Télécom and Olivier Levillain, Assistant Professor, Télécom SudParis – Institut Mines-Télécom
This article has been republished from The Conversation under a Creative Commons license. Read the original article.