Gaël Richard, a researcher in Information Processing at Télécom Paris, has been awarded an Advanced Grant from the European Research Council (ERC) for his project entitled HI-Audio. This initiative aims to develop hybrid approaches that combine signal processing with deep machine learning for the purpose of understanding and analyzing sound.
“Artificial intelligence now relies heavily on deep neural networks, which have a major shortcoming: they require very large databases for learning,” says Gaël Richard, a researcher in Information Processing at Télécom Paris. He believes that “using signal models, or physical sound propagation models, in a deep learning algorithm would reduce the amount of data needed for learning while still allowing for the high controllability of the algorithm.” Gaël Richard plans to pursue this breakthrough via his HI-Audio* project, which won an ERC Advanced Grant on April 26, 2022
For example, the integration of physical sound propagation models can improve the characterization and configuration of the types of sound analyzed and help to develop an automatic sound recognition system. “The applications for the methods developed in this project focus on the analysis of music signals and the recognition of sound scenes, which is the identification of the recording’s sound environment (outside, inside, airport) and all the sound sources present,” Gaël Richard explains.
Industrial applications
Learning sound scenes could help autonomous cars identify their surroundings. The algorithm would be able to identify the surrounding sounds using microphones. The vehicle would be able to recognize the sound of a siren and its variations in sound intensity. Autonomous cars would then be able to change lanes to let an ambulance or fire engine pass, without having to “see” it in the detection cameras. The processes developed in the HI-Audio project could be applied to many other areas. The algorithms could be used in predictive maintenance to control the quality of parts in a production line. A car part, such as a bumper, is typically controlled based on the sound resonance generated when a non-destructive impact is applied.
The other key applications for the HI-Audio project are in the field of AI for music, particularly to assist musical creation by developing new interpretable methods for sound synthesis and transformation.
Machine learning and music
“One of the goals of this project is to build a database of music recordings from a wide variety of styles and different cultures,” Gaël Richard explains. “This database, which will be automatically annotated (with precise semantic information), will expand the research to include less studied or less distributed music, especially from audio streaming platforms,” he says. One of the challenges of this project is that of developing algorithms capable of recognizing the words and phrases spoken by the performers, retranscribing the music regardless of its recording location, and contributing new musical transformation capabilities (style transfer, rhythmic transformation, word changes).
“One important aspect of the project will also be the separation of sound sources,” Gaël Richard says. In an audio file, the separation of sources, which in the case of music are each linked to a different instrument, is generally achieved via filtering or “masking”. The idea is to hide all other sources until only the target source remains. One less common approach is to isolate the instrument via sound synthesis. This involves analyzing the music to characterize the sound source to be extracted in order to reproduce it. For Gaël Richard, “the advantage is that, in principle, artifacts from other sources are entirely absent. In addition, the synthesized source can be controlled by a few interpretable parameters, such as the fundamental frequency, which is directly related to the sound’s perceived pitch,” he says. “This type of approach opens up tremendous opportunities for sound manipulation and transformation, with real potential for developing new tools to assist music creation,” says Gaël Richard.
*HI-Audio will start on October 1st, 2022 and will be funded by the ERC Advanced Grant for five years for a total amount of €2.48 million.
Rémy Fauvel
https://imtech-test.imt.fr/wp-content/uploads/2022/05/Signal-N2.png641887I'MTechI'MTech2022-06-15 15:50:582022-06-15 17:19:07Audio and machine learning: Gaël Richard’s award-winning project
As medicine and genetics make increasing use of data science and AI, the question of how to protect this sensitive information is becoming increasingly important to all those involved in health. A team from the LaTIM laboratory is working on these issues, with solutions such as encryption and watermarking. It has just been accredited by Inserm.
Securing medical data, preventing it from being misused for commercial or malicious purposes, from being distorted or even destroyed has become a major challenge for both health players and public authorities. This is particularly relevant at a time when progress in medicine (and genetics) is increasingly based on the use of huge quantities of data, particularly with the rise of artificial intelligence. Several recent incidents (cyber-attacks, data leaks, etc.) have highlighted the urgent need to act against this type of risk. The issue also concerns each and every one of us: no one wants their medical information to be accessible to everyone.
“Health data, which is particularly sensitive, can be sold at a higher price than bank data,” points out Gouenou Coatrieux, a teacher-researcher at LaTIM (the Medical Information Processing Laboratory, shared by IMT Atlantique, the University of Western Brittany (UBO) and Inserm), who is working on this subject in conjunction with Brest University Hospital. To enable this data to be shared while also limiting the risks, LaTIM are usnig two techniques: secure computing and watermarking.
Secure computing, which combines a set of cryptographic techniques for distributed computing along with other approaches, ensures confidentiality: the externalized data is coded in such a way that it is possible to continue to perform calculations on it. The research organisation that receives the data – be it a public laboratory or private company – can study it, but doesn’t have access to its initial version, which it cannot reconstruct. They therefore remain protected.
Gouenou Coatrieux, teacher-researcher at LaTIM (Laboratoire de traitement de l’information médicale, common to IMT Atlantique, Université de Bretagne occidentale (UBO) and Inserm
Discreet but effective tattooing
Tattooing involves introducing a minor and imperceptible modification into medical images or data entrusted to a third party. “We simply modify a few pixels on an image, for example to change the colour a little, a subtle change that makes it possible to code a message,” explains Gouenou Coatrieux. We can thus tattoo the identifier of the last person to access the data. This method does not prevent the file from being used, but if a problem occurs, it makes it very easy to identify the person who leaked it. The tattoo thus guarantees traceability. It also creates a form of dissuasion, because users are informed of this device. This technique has long been used to combat digital video piracy. Encryption and tattooing can also be combined: this is called crypto-tattooing.
Initially, LaTIM team was interested in the protection of medical images. A joint laboratory was thus created with Medecom, a Breton company specialising in this field, which produces software dedicated to radiology.
Multiple fields of application
Subsequently, LaTIM extended its field of research to the entire field of cyber-health. This work has led to the filing of several patents. A former doctoral student and engineer from the school has also founded a company, WaToo, specialising in data tagging. A Cyber Health team at LaTIM, the first in this field, has just been accredited by Inserm. This multidisciplinary team includes researchers, research engineers, doctoral students and post-docs, and includes several fields of application: protection of medical images and genetic data, and ‘big data’ in health. In particular, it works on the databases used for AI and deep learning, and on the security of treatments that use AI. “For all these subjects, we need to be in constant contact with health and genetics specialists,” stresses Gouenou Coatrieux, head of the new entity. We also take into account standards in the field such as DICOM, the international standard for medical imaging, and legal issues such as those relating to privacy rights with the application of European RGPD regulations.
The Cyber Health team recently contributed to a project called PrivGen, selected by the Labex (laboratory of excellence) CominLabs. The ongoing work which started with PrivGen aims to identify markers of certain diseases in a secure manner, by comparing the genomes of patients with those of healthy people, and to analyse some of the patients’ genomes. But the volumes of data and the computing power required to analyse them are so large that they have to be shared and taken out of their original information systems and sent to supercomputers. “This data sharing creates an additional risk of leakage or disclosure,” warns the researcher. “PrivGen’s partners are currently working to find a technical solution to secure the treatments, in particular to prevent patient identification”.
Towards the launch of a chaire (French research consortium)
An industrial chaire called Cybaile, dedicated to cybersecurity for trusted artificial intelligence in health, will also be launched next fall. LaTIM will partner with three other organizations: Thales group, Sophia Genetics and the start-up Aiintense, a specialist in neuroscience data. With the support of Inserm, and with the backing of the Regional Council of Brittany, it will focus in particular on securing the learning of AI models in health, in order to help with decision-making – screening, diagnoses, and treatment advice. “If we have a large amount of data, and therefore representations of the disease, we can use AI to detect signs of anomalies and set up decision support systems,” says Gouenou Coatrieux. “In ophthalmology, for example, we rely on a large quantity of images of the back of the eye to identify or detect pathologies and treat them better.“
https://imtech-test.imt.fr/wp-content/uploads/2022/06/Visuel_tatouage_donnees_sante.jpg8901280I'MTechI'MTech2022-06-13 15:54:042022-06-13 16:02:49Encrypting and watermarking health data to protect it
Director of Teralab, IMT’s Big Data and AI platform, since 2015, Anne-Sophie Taillandier was elected member of the Academy of technologies in March 2022. This election is in recognition of her work developing projects on data and artificial intelligence at national and European level.
Newly elected to the Academy of Technologies, Anne-Sophie Taillandier has been Director of Teralab for seven years, a platform created by IMT in 2012 that specializes in Big Data and Artificial Intelligence. Anne-Sophie Taillandier was drawn towards a scientific occupation as she “always found mathematics enjoyable,” she says. “This led me to study science, first in an engineering school, at CentraleSupélec, and then to complete a doctoral thesis in Applied Mathematics at the ENS, which I defended in 1998,” she adds.
Once her thesis in Artificial Intelligence was completed, she joined Dassault Systèmes. “After my thesis, I wanted to see an immediate application of the things I had learned, so I joined Dassault Systèmes where I held various positions,” says Anne-Sophie Taillandier. During the ten years she spent at the well-known company, she contributed to the development of modeling software, worked in Human Resources, and led the Research & Development department of the brand Simulia. In 2008, she moved to an IT security company, and then in 2012 became Director of Technology at LTU Technologies, an image recognition software company, until 2015, when she took over the management of Teralab at IMT.
“It was the opportunity to work in a wide variety of fields while focusing on data, machine learning, and its applications that prompted me to join Teralab,” says Anne-Sophie Taillandier. Working with diverse companies requires “understanding a profession to grasp the meaning of the data that we are manipulating”. For the Director of Teralab, this experience mirrored that of her thesis, during which she had to understand the meaning of data provided by automotive engineers in order to manipulate it appropriately.
Communicating and explaining
In the course of her career, Anne-Sophie Taillandier realized “that there were language barriers, that there were sometimes difficulties in understanding each other”. She has taken a particular interest in these problems. “I’ve always found it interesting to take an educational approach to explain our work, to try to hide the computational and mathematical complexity in simple language,” says the Teralab director. “Since its inception, Teralab has aimed to facilitate the use of sophisticated technology, and to understand the professions of people who hold the data,” she says.
Teralab positions itself as an intermediary between companies and researchers so that they may understand each other and cooperate. In this project, it is necessary to make different disciplines work together. A technology watch is also important to remain up to date with the latest innovations, which can be better suited to a client’s needs. In addition, Teralab has seen new issues arise during its eight years of existence.
“We realized that the users who came to us in the beginning wanted to work on their own data, whereas today they want to work in an ecosystem that allows the circulation of their data. This raises issues of control over the use of their data, as well as of architecture and exchange standards,” points out Anne-Sophie Taillandier. The pooling of data held by different companies raises issues of confidentiality, as they may be in competition on certain points.
European recognition
“At TeraLab, we asked ourselves about data sharing between companies, which led us to the Gaia-X initiative”. In this European association, Teralab and other companies participate in the development of services to create a ‘cloud federation’. This is essential as a basis for enabling the flow of data, interoperability, and avoiding confining companies to ‘cloud’ solutions. Europe’s technological independence depends on these types of regulations and standards. Not only would companies be able to protect their digital assets and make informed choices, but they would also be able to share information with each other, under suitable conditions according to the sensitivity of their data.
In the development of Gaia-X federated services and the creation of data spaces, Teralab provides its technological and human resources to validate architecture, to prototype new services on sector-specific data spaces, and to build the open-source software layer that is essential to this development. “If EDF or another critical infrastructure, like banking, wants to be able to move sensitive data into these data spaces, they will need both technical and legal guarantees.”.
Teralab, since the end of the public funding that it received until 2018, has not stopped growing, especially at European level. “We currently have a European project on health-related data on cardiovascular diseases,” says the Teralab director. The goal is for researchers in European countries who need data on these diseases to be able to conduct research via a DataHub – a space for sharing data. In the future, Teralab’s goal is to continue its work in cloud federation and to “become a leading platform for the creation of digital ecosystems,” says Anne-Sophie Taillandier.
Rémy Fauvel
https://imtech-test.imt.fr/wp-content/uploads/2022/03/Anne-Sophie_Taillandier-rcadre.jpg8181193I'MTechI'MTech2022-05-02 15:43:302022-05-02 15:43:31Anne-Sophie Taillandier: New member of the Academy of technologies
There has been constant development in the area of object interconnection via the internet. And this trend is set to continue in years to come. One of the solutions for machines to communicate with each other is the Semantic Web. Here are some explanations of this concept.
“The Semantic Web gives machines similar web access to that of humans,” indicates Maxime Lefrançois, Artificial Intelligence researcher at Mines Saint-Etienne. This area of the web is currently being used by companies to gather and share information, in particular for users. It makes it possible to adapt product offers to consumer profiles, for example. At present, the Semantic Web occupies an important position in research undertaken around the Internet of Things, i.e. the interconnection between machines and objects connected via the internet.
By making machines work together, the Internet of Things can be a means of developing new applications. This would serve both individuals and professional sectors, such as intelligent buildings or digital agriculture. The last two examples are also the subject of the CoSWoT1 project, funded by the French National Research Agency (ANR). This initiative, in which Maxime Lefrançois is participating, aims to provide new knowledge around the use of the Semantic Web by devices.
To do so, the projects’ researchers installed sensors and actuators in the INSA Lyon buildings on the LyonTech-la Doua campus, the Espace Fauriel building of Mines Saint-Etienne, and the INRAE experimental farm in Montoldre. These sensors record information, like the opening of a window or the temperature and CO2 levels in a room. Thanks to a digital representation of a building or block, scientists can construct applications that use the information provided by sensors, enrich it and make decisions that are transmitted to actuators.
Such applications can measure the CO2 concentration in a room, and according to a pre-set threshold, open the windows automatically for fresh air. This could be useful in the current pandemic context, to reduce the viral load in the air and thereby reduce the risk of infection. Beyond the pandemic, the same sensors and actuators can be used in other cases for other purposes, such as to prevent the build-up of pollutants in indoor air.
A dialog with cards
The main characteristic of the Semantic Web is that it registers information in knowledge graphs: kinds of maps made up of nodes representing objects, machines or concepts, and arcs that connect them to one another, representing their relationships. Each hub and arc is registered with an Internationalized Resource Identifier (IRI): a code that makes it possible for machines to recognize each other and identify and control objects such as a window, or concepts such as temperature.
Depending on the number of knowledge graphs built up and the amount of information contained, a device will be able to identify objects and items of interest with varying degrees of precision. A graph that recognizes a temperature identifier will indicate, depending on its accuracy, the unit used to measure it. “By combining multiple knowledge graphs, you obtain a graph that is more complete, but also more complex,” declares Lefrançois. “The more complex the graph, the longer it will take for the machine to decrypt,” adds the researcher.
Means to optimize communication
The objective of the CoSWoT project is to simplify dialog between autonomous devices. It is a question of ‘integrating’ the complex processing linked with the Semantic Web into objects with low calculating capabilities and limiting the amount of data exchanged in wireless communication to preserve their batteries. This represents a challenge for Semantic Web research. “It needs to be possible to integrate and send a small knowledge graph in a tiny amount of data,” explains Lefrançois. This optimization makes it possible to improve the speed of data exchanges and related decision-making, as well as to contribute greater energy efficiency.
With this in mind, the researcher is interested in what he calls ‘semantic interoperability’, with the aim of “ensuring that all kinds of machines understand the content of messages that they exchange,” he states. Typically, a connected window produced by one company must be able to be understood by a CO2 sensor developed by another company, which itself must be understood by the connected window. There are two approaches to achieve this objective. “The first is that machines use the same dictionary to understand their messages,” specifies Lefrançois, “The second involves ensuring that machines solve a sort of treasure hunt to find how to understand the messages that they receive,” he continues. In this way, devices are not limited by language.
IRIs in service of language
Furthermore, solving these treasure hunts is allowed by IRIs and the use of the web. “When a machine receives an IRI, it does not need to automatically know how to use it,” declares Lefrancois. “If it receives an IRI that it does not know how to use, it can find information on the Semantic Web to learn how,” he adds. This is analogous to how humans may search for expressions that they do not understand online, or learn how to say a word in a foreign language that they do not know.
However, for now, there are compatibility problems between various devices, due precisely to the fact that they are designed by different manufacturers. “In the medium term, the CoSWoT project could influence the standardization of device communication protocols, in order to ensure compatibility between machines produced by different manufacturers,” the researcher considers. It will be a necessary stage in the widespread roll-out of connected objects in our everyday lives and in companies.
While research firms are fighting to best estimate the position that the Internet of Things will hold in the future, all agree that the world market for this sector will represent hundreds of billions of dollars in five years’ time. As for the number of objects connected to the internet, there could be as many as 20 to 30 billion by 2030, i.e. far more than the number of humans. And with the objects likely to use the internet more than us, optimizing their traffic is clearly a key challenge.
[1] The CoSWoT project is a collaboration between the LIMOS laboratory (UMR CNRS 6158 which includes Mines Saint-Étienne), LIRIS (UMR CNRS 5205), Hubert Curien laboratory (UMR CNRS 5516) INRAE, and the company Mondeca.
https://imtech-test.imt.fr/wp-content/uploads/2022/02/Image-IOT.jpg12801920I'MTechI'MTech2022-04-05 15:02:512022-04-05 15:02:52Machines surfing the web
In conjunction with the GIS BeAChild, the AI-4-Child team is using artificial intelligence to analyze images related to cerebral palsy in children. This could lead to better diagnoses, innovative therapies and progress in patient rehabilitation. But also a real breakthrough in medical imaging.
Cerebral palsy is the leading cause of motor disability in children, affecting nearly two out of every 1,000 newborns. And it is irreversible. The AI-4-Child chaire (French research consortium), managed by IMT Atlantique and the Brest University Hospital, is dedicated to fighting this dreaded disease, using artificial intelligence and deep learning, which could eventually revolutionize the field of medical imaging.
“Cerebral palsy is the result of a brain lesion that occurs around birth,” explains François Rousseau, head of the consortium, professor at IMT Atlantique and a researcher at the Medical Information Processing Laboratory (LaTIM, INSERM unit). “There are many possible causes – prematurity or a stroke in utero, for example. This lesion, of variable importance, is not progressive. The resulting disability can be more or less severe: some children have to use a wheelchair, while others can retain a certain degree of independence.”
Created in 2020, AI-4-Child brings together engineers and physicians. The result of a call for ‘artificial intelligence’ projects from the French National Research Agency (ANR), it operates in partnership with the company Philips and the Ildys Foundation for the Disabled, and benefits from various forms of support (Brittany Region, Brest Metropolis, etc.). In total, the research program has a budget of around €1 million for a period of five years.
François Rousseau, professor at IMT Atlantique and head of the AI-4-Child chaire (research consortium)
Hundreds of children being studied in Brest
AI-4-Child works closely with BeAChild*, the first French Scientific Interest Group (GIS) dedicated to pediatric rehabilitation, headed by Sylvain Brochard, professor of physical medicine and rehabilitation (MPR). Both structures are linked to the LaTIM lab (INSERM UMR 1101), housed within the Brest CHRU teaching hospital. The BeAChild team is also highly interdisciplinary, bringing together engineers, doctors, pediatricians and physiotherapists, as well as psychologists.
Hundreds of children from all over France and even from several European countries are being followed at the CHRU and at Ty Yann (Ildys Foundation). By bringing together all the ‘stakeholders’ – patients and families, health professionals and imaging specialists – on the same site, Brest offers a highly innovative approach, which has made it a reference center for the evaluation and treatment of cerebral palsy. This has enabled the development of new therapies to improve children’s autonomy and made it possible to design specific applications dedicated to their rehabilitation.
“In this context, the mission of the chair consists of analyzing, via artificial intelligence, the imagery and signals obtained by MRI, movement analysis or electroencephalograms,” says Rousseau. These observations can be made from the fetal stage or during the first years of a child’s life. The research team is working on images of the brain (location of the lesion, possible compensation by the other hemisphere, link with the disability observed, etc.), but also on images of the neuro-musculo-skeletal system, obtained using dynamic MRI, which help to understand what is happening inside the joints.
‘Reconstructing’ faulty images with AI
But this imaging work is complex. The main pitfall is the poor quality of the images collected, due to camera shake or artifacts during the shooting. So AI-4-Child is trying to ‘reconstruct’ them, using artificial intelligence and deep learning. “We are relying in particular on good quality views from other databases to achieve satisfactory resolution,” explains the researcher. Eventually, these methods should be able to be applied to routine images.
Significant progress has already been made. A doctoral student is studying images of the ankle obtained in dynamic MRI and ‘enriched’ by other images using AI – static images, but in very high resolution. “Despite a rather poor initial quality, we can obtain decent pictures,” notes Rousseau. Significant differences between the shapes of the ankle bone structure were observed between patients and are being interpreted with the clinicians. The aim will then be to better understand the origin of these deformations and to propose adjustments to the treatments under consideration (surgery, toxin, etc.).
The second area of work for AI-4-Child is rehabilitation. Here again, imaging plays an important role: during rehabilitation courses, patients’ gait is filmed using infrared cameras and a system of sensors and force plates in the movement laboratory at the Brest University Hospital. The ‘walking signals’ collected in this way are then analyzed using AI. For the moment, the team is in the data acquisition phase.
Several areas of progress
The problem, however, is that a patient often does not walk in the same way during the course and when they leave the hospital. “This creates a very strong bias in the analysis,” notes Rousseau. “We must therefore check the relevance of the data collected in the hospital environment… and focus on improving the quality of life of patients, rather than the shape of theirbones.”
Another difficulty is that the data sets available to the researchers are limited to a few dozen images – whereas some AI applications require several million, not to mention the fact that this data is not homogeneous, and that there are also losses. “We have therefore become accustomed to working with little data,” says Rousseau. “We have to make sure that the quality of the data is as good as possible.” Nevertheless, significant progress has already been made in rehabilitation. Some children are able to ride a bike, tie their shoes, or eat independently.
In the future, the AI-4-Child team plans to make progress in three directions: improving images of the brain, observing bones and joints, and analyzing movement itself. The team also hopes to have access to more data, thanks to a European data collection project. Rousseau is optimistic: “Thanks to data processing, we may be able to better characterize the pathology, improve diagnosis and even identify predictive factors for thedisease.”
* BeAChild brings together the Brest University Hospital Centre, IMT Atlantique, the Ildys Foundation and the University of Western Brittany (UBO). Created in 2020 and formalized in 2022 (see the French press release), the GIS is the culmination of a collaboration that began some fifteen years ago on the theme of childhood disability.
https://imtech-test.imt.fr/wp-content/uploads/2022/01/Visuel-Une-Ildys.jpg8901386I'MTechI'MTech2022-03-29 10:31:252022-03-29 10:34:07AI-4-Child “Chaire” research consortium: innovative tools to fight against childhood cerebral palsy
Given that catastrophic events are rare by nature, it is difficult to prepare for them. However, artificial intelligence offers high-performing tools for modeling and simulation, and is therefore an excellent tool to design, test and optimize the response to such events. At IMT Mines Alès, Satya Lancel and Cyril Orengo are both undertaking research on emergency evacuations, in case of events like a dam breaking or a terrorist attack in a supermarket.
“Supermarkets are highly complex environments in which individuals are saturated with information,” explains Satya Lancel, PhD student in Risk Science at Université Montpellier III and IMT Mines Alès. Her thesis, which she started over two years ago, is on the subject of affordance, a psychological concept that states that an object or element in the environment is able to suggest its own use. With this research, she wishes to study the link between the cognitive processes involved in decision-making and the functionality of objects in their environment.
In her thesis, Lancel specifically focuses on affordance in the case of an armed attack within a supermarket. She investigates, for example, how to optimize instructions to encourage customers to head towards emergency evacuation exits. “The results of my research could act as a foundation for future research and be used by supermarket brands to improve signage or staff training, in order to improve evacuation procedures”, she explains.
Lancel and her team obtained funding from the brand U to perform their experiments. This agreement allowed them to study the situational and cognitive factors involved in customer decision-making in several U stores. “One thing we did in the first part of my research plan was to observe customer behavior when we added or removed flashing lights at the emergency exits,” she describes. “We remarked that when there was active signage, customers are more likely to decide to head towards the emergency exits than when there was not,” says the scientist. This result suggests that signage has a certain level of importance in guiding people’s decision-making, even if they do not know the evacuation procedure in advance.
“Given that it is forbidden to perform simulations of armed attacks with real people, we opted for a multi-agent digital simulation”, explains Lancel. What is unique about this kind of simulation is that each agent involved is conceptualized as an autonomous entity with its own characteristics and behavioral model. In these simulations, the agents interact and influence each other with their behavior. “These models are now used more and more in risk science, as they are proving to be extremely useful for analyzing group behavior,” she declares.
To develop this simulation, Lancel collaborated with Vincent Chapurlat, digital systems modeling researcher at IMT Mines Alès. “The model we designed is a three-dimensional representation of the supermarket we are working on,” she indicates. In the simulation, aisles are represented by parallepipeds, while customers and staff are represented by agents defined by points. By observing how agents gather and how the clusters they form move around, interact and organize themselves, it is possible to determine which group behaviors are most common in the event of an armed attack, no matter the characteristics of the individuals.
Representing the complexity of reality
Outside of supermarkets, Cyril Orengo, PhD student in Crisis Management at the Risk Science Laboratory at IMT Mines Alès, is studying population evacuation in the event of dam failure. The case study chosen by Orengo is the Sainte-Cécile-d’Andorge dam, near the city of Alès. Based on digital modeling of the Alès urban area and individuals, he plans to compare evacuation time for a range of scenarios and perform cartography of various city roads that are likely to be blocked. “One of the aims of this work is to build a knowledge base that could be used in the future by researchers working on preventive evacuations,” indicates the doctoral student.
He, too, has chosen to use a multi-agent system to simulate evacuations, as this method makes it possible to combine individual parameters with agents to produce situations that tend to be close to a credible reality. “Among the variables selected in my model are certain socio-economic characteristics of the simulated population,” he specifies. “In a real-life situation, an elderly person may take longer to go somewhere than a young person: the multi-agent system makes it possible to reproduce this,” explains the researcher.
To generate a credible simulation, “you first need to understand the preventive evacuation process,” underlines Orengo, specifying the need “to identify the actors involved, such as citizens and groups, as well as the infrastructure, such as buildings and traffic routes, in order to produce a model to act as a foundation to develop the digital simulation”. As part of his work, the PhD student analyzed INSEE databases to try and reproduce the socioeconomic characteristics of the Alès population. Orengo used a specialized platform for building agent simulations to create his own. “This platform allows researchers without computer programming training to create models, controlling various parameters that they define themselves,” explains the doctoral student. One of the limitations of this kind of simulation is computing power, which means only a certain number of variables can be taken into account. According to Orengo, his model still needs many improvements. These include “integrating individual vehicles, public transport, decision-making processes relating to risk management and more detailed reproduction of human behaviors”, he specifies. For Lancel, virtual reality could be an important addition, increasing participants’ immersion in the study, “By placing a participant in a virtual crowd, researchers could observe how they react to certain agents and their environment, which would allow them to refine their research,” she concludes.
Rémy Fauvel
https://imtech-test.imt.fr/wp-content/uploads/2021/12/Visuel_Une-2.jpg8901380I'MTechI'MTech2022-03-14 16:09:312022-03-15 11:41:55Planning for the worst with artificial intelligence
Individual cars represent a major source of pollution. But how can you transition from using your own car when you live far from the city center, in an area with little access to public transport? Andrea Araldo, researcher at Télécom SudParis is undertaking a research project that aims to redesign city accessibility, to benefit those excluded from urban mobility.
The transport sector is responsible for 30% of greenhouse gas emissions in France. And when we look more closely, the main culprit appears clearly: individual cars, responsible for over half of the CO2 discharged into the atmosphere by all modes of transport.
To protect the environment, car drivers are therefore thoroughly encouraged to avoid using their car, instead opting for a means of transport that pollutes less. However, this shift is impeded by the uneven distribution of public transport in urban areas. Because while city centers are generally well connected, accessibility proves to be worse on the whole in the suburbs (where walking and waiting times are much longer). This means that personal cars appear to be the only viable option in these areas.
The MuTAS (Multimodal Transit for Accessibility and Sustainability) project, selected by the National Research Agency (ANR) as part of the 2021 general call for projects, aims to reduce these accessibility inequalities at the scale of large cities. The idea is to provide the keys to offering a comprehensive, equitable and multimodal range of mobility options, combining public transport with fixed routes and schedules with on-demand transport services, such as chauffeured cars or rideshares. These modes of transport could pick up where buses and trains leave off in less-connected zones. “In this way, it is a matter of improving accessibility of the suburbs, which would allow residents to leave their personal car in the garage and take public transport, thereby contributing to reducing pollution and congestion on the roads”, says Andrea Araldo, researcher at Télécom SudParis and head of the MuTAS project, but formerly a driving school owner and instructor!
Improving accessibility without sending costs sky-high
But how can on-demand mobility be combined with the range of public transport, without leading to overblown costs for local authorities? The budget issue remains a central challenge for MuTAS. The idea is not to deploy thousands of vehicles on-demand to improve accessibility, but rather to make public transport more equitable within urban areas, for an equivalent cost (or with a limited increase).
This means that many questions must be answered, while respecting this constraint. In which zones should on-demand mobility services be added? How many vehicles need to be deployed? How can these services be adapted to different times throughout the day? And there are also questions regarding public transport. How can bus and train lines be optimized, to efficiently coordinate with on-demand mobility? Which are the best routes to take? Which stations can be eliminated, definitively or only at certain times?
To resolve this complex optimization issue, Araldo and his teams have put forward a strategy using artificial intelligence, in three phases.
Optimizing a graph…
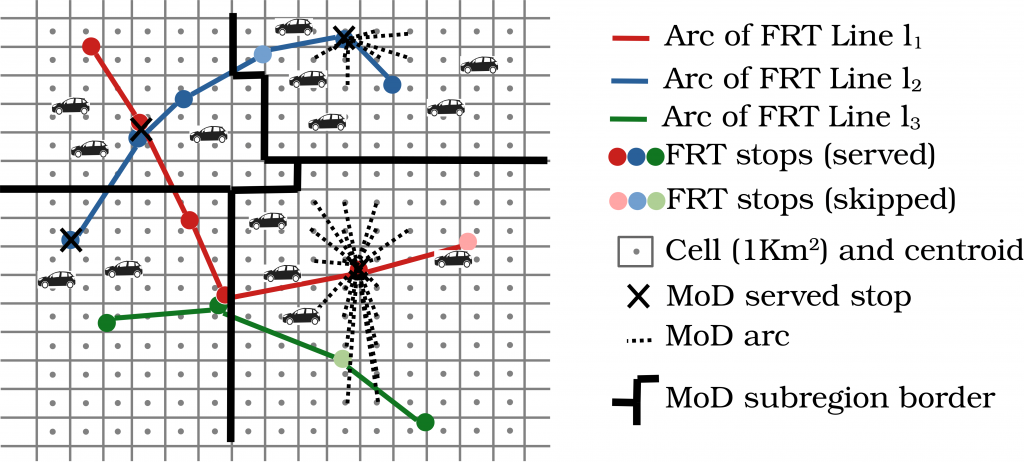
The first involves modeling the problem in the form of a graph. In this graph, the points correspond to bus stops or train stations, with each line represented by a series of arcs, each with a certain trip time. “What must be noted here is that we are only using real-life, public data,” emphasizes Araldo. “Other research has been undertaken around these issues, but at a more abstract level. As part of MuTAS, we are using openly available, standardized data, provided by several cities around the world, including routes, schedules, trip times etc., but also population density statistics. This means we are modeling real public transport systems.” On-demand mobility is also added to the graph in the form of arcs, connecting less accessible areas to points in the network. This translates the idea of allowing residents far from the city center to get to a bus or train station using chauffeured cars or rideshares.
To optimize travel in a certain area, researchers start by modeling public transport lines with a graph.
…using artificial intelligence
This modeled graph acts as the starting point for the second phase. In this phase, a reinforcement learning algorithm is introduced, a method from the field of machine learning. After several iterations, this is what will determine what improvements need to be made to the network, for example, deactivating stations, eliminating lines, adding on-demand mobility services, etc. “Moreover, the system must be capable of adapting its structure dynamically, according to shifts in demand throughout the day,” adds the researcher. “The traditional transport network needs to be dense and extended during peak hours, but it can contract significantly in off-peak hours, with on-demand mobility taking over for the last kilometers, which is more efficient for lower numbers ofpassengers.”
And that is not the only complex part. Various decisions influence each other: for example, if a bus line is removed from a certain place, more rideshares or chauffeured car services will be needed to replace it. So, the algorithm applies to both public transport and on-demand mobility. The objective will therefore be to reach an optimal situation in terms of equitable distribution of accessibility.
But how can this accessibility be evaluated? There are multiple methods to do so, but researchers have chosen two adapted methods for graph optimization. The first is a ‘velocity score’, corresponding to the maximum distance that can be traveled from a departure point in a limited time (30 minutes for example). The second is a ‘sociality score’, representing the number of people that one can meet from a specific area, also within a limited time.
In concrete terms, the algorithm will take an indicator as a reference, i.e. a measure of the accessibility for the least accessible place in the area. The aim being to make transport options as equitable as possible, it will aim to optimize this indicator (‘max-min’ optimization), while respecting certain restrictions such as cost. To achieve this, it will make a series of decisions concerning the network, initially in a random way. Then, at the end of each iteration, by analyzing the flow of passengers, it will calculate the associated ‘reward’, the improvement in the reference indicator. The algorithm will then stop when the optimum is reached, or else after a pre-determined period.
This approach will allow it to establish knowledge of its environment, associating each network structure (according to the decisions made) with the expected reward. “The advantage of such an approach is that once the algorithm is trained, the knowledge base can be used for another network,” explains Araldo. “For example, I can use the optimization performed for Paris as a starting point for a similar project in Berlin. This represents a precious time-saver compared to traditional methods used to structure transport networks, in which you have to start each new project fromzero.”
Testing results on (virtual) users in Ile-de-France
Lastly, the final phase aims to validate the results obtained using a detailed model. While the models from the first phase aim to reproduce reality, they only represent a simplified version. This is important, given that they will then be used for various iterations, as part of the reinforcement learning process. If they had a very high level of detail, the algorithm would require a huge amount of computing power, or too much processing time.
The third phase therefore involves first delicately modeling the transport network in an urban area (in this case, the Ile-de-France region), still using real-life data, but more detailed this time. To integrate all this information, researchers use a simulator called SimMobility, developed at MIT in a project to which Araldo contributed. The tool makes it possible to simulate the behavior of populations at an individual level, each person represented by an ‘agent’ with their own characteristics and preferences (activities planned during the days, trips to take, desire to reduce walking time or minimize number of changes, etc.). It was based on the work of Daniel McFadden (Nobel Prize for Economics in 2000) and Moshe Ben-Akiva on ‘discrete choice models’, which makes it possible to predict choices between multiple modes of transport.
With the help of this simulator and public databases (socio-demographic studies, road networks, numbers of passengers, etc.), Araldo and his team, in collaboration with MIT, will generate a synthetic population, representing Ile-de-France users, with a calibration phase. Once the model faithfully reproduces reality, it will be possible to submit it to the new optimized transport system and simulate user reactions. “It is important to always remember that it’s only a simulation,” reminds the researcher. “While our approach allows us to realistically predict user behavior, it certainly does not correspond 100% to reality. To get closer, more detailed analysis and deeper collaborations with transport management bodies will beneeded.”
Nevertheless, results obtained could serve to support more equitable urban mobility and in time, reduce its environmental footprint. Especially since the rise of electric vehicles and automation could increase the environmental benefits. However, according to Araldo, “electric, self-driving cars do not represent a miracle solution to save the planet. They will only prove to be a truly eco-friendly option as part of a multimodal public transportnetwork.”
Bastien Contreras
https://imtech-test.imt.fr/wp-content/uploads/2022/01/Visuel_Une-1.jpg8911380I'MTechI'MTech2022-03-07 16:52:002022-04-20 11:12:37“En route” to more equitable urban mobility, thanks to artificial intelligence
Digital innovations are paving the way for more accurate predictive medicine and a more resilient healthcare system. In order to establish themselves on the market and reduce their potential negative effects, these technologies must be responsible. Christine Balagué, a researcher in digital ethics at Institut Mines-Télécom Business School, presents the risks associated with innovations in the health sector and ways to avoid them.
“Until now, the company has approached technology development without looking at the environmental and social impacts of the digital innovations produced. The time has come to do something about this, especially when it comes to human lives in the health sector”, says Christine Balagué, a researcher at Institut Mines-Telecom Business School and co-holder of the Good in Tech Chair [1]. From databases and artificial intelligence for detecting and treating rare diseases, to connected objects for monitoring patients; the rapid emergence of tools for prediction, diagnosis and also business organization is making major changes in the healthcare sector. Similarly, the goal of a smarter hospital of the future is set to radically change the healthcare systems we know today. The focus is on building on medical knowledge, advancing medical research, and improving care.
However, for Christine Balagué, a distinction must be made between the notion of “tech for good” – which consists of developing systems for the benefit of society – and “good in tech”. She says “an innovation, however benevolent it may be, is not necessarily devoid of bias and negative effects. It’s important not to stop at the positive impacts but to also measure the potential negative effects in order to eliminate them.” The time has come for responsible innovation. In this sense, the Good in Tech chair, dedicated to responsibility and ethics in digital innovations and artificial intelligence, aims to measure the still underestimated environmental and societal impacts of technologies on various sectors, including health.
Digital innovations: what are the risks for healthcare systems?
In healthcare, it is clear: an algorithm that cannot be explained is unlikely to be commercialized, even if it is efficient. Indeed, the potential risks are too critical when human lives are at stake. However, a study published in 2019 in the journal Science on the use of commercial algorithms in the U.S. health care system demonstrated the presence of racial bias in the results of these tools. This discrimination between patients, or between different geographical areas, therefore gives rise to an initial risk of unequal access to care. “The more automated data processing becomes, the more inequalities are created,” says Christine Balagué. However, machine learning is increasingly being used in the solutions offered to healthcare professionals.
For example, French start-ups such as Aiintense, incubated at IMT Starter, and BrainTale use it for diagnostic purposes. Aiintense is developing decision support tools for all pathologies encountered in intensive care units. BrainTale is looking at the quantification of brain lesions. These two examples raise the question of possible discrimination by algorithms. “These cases are interesting because they are based on work carried out by researchers and have been recognized internationally by the scientific peer community, but they use deep learning models whose results are not entirely explainable. This therefore hinders their application by intensive care units, which need to understand how these algorithms work before making major decisions about patients,” says the researcher.
Furthermore, genome sequencing algorithms raise questions about the relationship between doctors and their patients. Indeed, the limitations of the algorithm, the presence of false positives or false negatives are rarely presented to patients. In some cases, this may lead to the implementation of unsuitable treatments or operations. It is also possible that an algorithm may be biased by the opinion of its designer. Finally, unconscious biases associated with the processing of data by humans can also lead to inequalities. Artificial intelligence in particular thus raises many ethical questions about its use in the healthcare setting.
What do we mean by a “responsible innovation”? It is not just a question of complying with data processing laws and improving the health care professional’s way of working. “We must go further. This is why we want to measure two criteria in new technologies: their environmental impact and their societal impact, distinguishing between the potential positive and negative effects for each. Innovations should then be developed according to predefined criteria aimed at limiting their negative effects,” says Christine Balagué.
Changing the way innovations are designed
Liability is not simply a layer of processing that can be added to an existing technology. Thinking about responsible innovation implies, on the contrary, changing the very manner in which innovations are designed. So how do we ensure they are responsible? Scientists are looking for precise indicators that could result in a “to do list” of criteria to be verified. This starts with the analysis of the data used for learning, but also by studying the interface developed for the users, through the architecture of the neural network that can potentially generate bias. On the other hand, existing environmental criteria must be refined by taking into account the design chain of a connected object and the energy consumption of the algorithms. “The criteria identified could be integrated into corporate social responsibility in order to measure changes over time,” says Christine Balagué.
In the framework of the Good In Tech chair, several research projects, including a thesis, are being carried out on our capacity to explain algorithms. Among them, Christine Balagué and Nesma Houmani (a researcher at Télécom SudParis) are interested in algorithms for electroencephalography (EEG) analysis. Their objective is to ensure that the tools use interfaces that can be explained to health care professionals, the future users of the system. “Our interviews show that explaining how an algorithm works to users is often something that designers aren’t interested in, and that making it explicit would be a source of change in the decision-making process,” says the researcher. The ability to explain and interpret results are therefore two key words guiding responsible innovation.
Ultimately, the researchers have identified four principles that an innovation in healthcare must follow. The first is anticipation in order to measure the potential benefits and risks upstream of the development phase. Then, a reflexive approach allows the designer to limit the negative effects and to integrate into the system itself an interface to explain how the technological innovation works to physicians. It must also be inclusive, i.e. reaching all patients throughout the territory. Finally, responsive innovation facilitates rapid adaptation to the changing context of healthcare systems. Christine Balagué concludes: “Our work shows that taking into account ethical criteria does not reduce the performance of algorithms. On the contrary, taking into account issues of responsibility helps to promote the acceptance of an innovation on the market”.
[1]The Chair is supported by the Institut Mines-Télécom Business School, the School of Management and Innovation at Sciences Po, and the Fondation du Risque, in partnership with Télécom Paris and Télécom SudParis.
https://imtech-test.imt.fr/wp-content/uploads/2021/04/Visuel_Une-Innovation_en_sante-Place-a-la-responsabilite.jpg8901380I'MTechI'MTech2021-04-15 15:25:022021-04-15 15:25:58Innovation in health: towards responsibility
In recent decades, algorithms have become increasingly complex, particularly through the introduction of deep learning architectures. This has gone hand in hand with increasing difficulty in explaining their internal functioning, which has become an important issue, both legally and socially. Winston Maxwell, legal researcher, and Florence d’Alché-Buc, researcher in machine learning, who both work for Télécom Paris, describe the current challenges involved in the explainability of algorithms.
What skills are required to tackle the problem of algorithm explainability?
Winston Maxwell: In order to know how to explain algorithms, we must draw on different disciplines. Our multi-disciplinary team, AI Operational Ethics, focuses not only on mathematical, statistical and computational aspects, but also on sociological, economic and legal aspects. For example, we are working on an explainability system for image recognition algorithms used, among other things, for facial recognition in airports. Our work therefore encompasses these different disciplines.
Why are algorithms often difficult to understand?
Florence d’Alché-Buc:Initially, artificial intelligence used mainly symbolic approaches, i.e., it simulated the logic of human reasoning. Logical rules, called expert systems, allowed artificial intelligence to make a decision by exploiting observed facts. This symbolic framework made AI more easily explainable. Since the early 1990s, AI has increasingly relied on statistical learning, such as decision trees or neural networks, as these structures allow for better performance, learning flexibility and robustness.
This type of learning is based on statistical regularities and it is the machine that establishes the rules which allow their exploitation. The human provides input functions and an expected output, and the rest is determined by the machine. A neural network is a composition of functions. Even if we can understand the functions that compose it, their accumulation quickly becomes complex. So a black box is then created, in which it is difficult to know what the machine is calculating.
How can artificial intelligence be made more explainable?
FAB: Current research focuses on two main approaches. There is explainability by design where, for any new constitution of an algorithm, explanatory output functions are implemented which make it possible to progressively describe the steps carried out by the neural network. However, this is costly and impacts the performance of the algorithm, which is why it is not yet very widespread. In general, and this is the other approach, when an existing algorithm needs to be explained, it is an a posteriori approach that is taken, i.e., after an AI has established its calculation functions, we will try to dissect the different stages of its reasoning. For this there are several methods, which generally seek to break the entire complex model down into a set of local models that are less complicated to deal with individually.
Why do algorithms need to be explained?
WM: There are two main reasons why the law stipulates that there is a need for the explainability of algorithms. Firstly, individuals have the right to understand and to challenge an algorithmic decision. Secondly, it must be guaranteed that a supervisory institution such as the French Data Protection Authority (CNIL), or a court, can understand the operation of the algorithm, both as a whole and in a particular case, for example to make sure that there is no racial discrimination. There is therefore an individual aspect and an institutional aspect.
Does the format of the explanations need to be adapted to each case?
WM: The formats depend on the entity to which it needs to be explained: for example, some formats will be adapted to regulators such as the CNIL, others to experts and yet others to citizens. In 2015, an experimental service to deploy algorithms that detect possible terrorist activities in case of serious threats was introduced. For this to be properly regulated, an external control of the results must be easy to carry out, and therefore the algorithm must be sufficiently transparent and explainable.
Are there any particular difficulties in providing appropriate explanations?
WM: There are several things to bear in mind. For example, information fatigue: when the same explanation is provided systematically, humans will tend to ignore it. It is therefore important to use varying formats when presenting information. Studies have also shown that humans tend to follow a decision given by an algorithm without questioning it. This can be explained in particular by the fact that humans will consider from the outset that the algorithm is statistically wrong less often than themselves. This is what we call automation bias. This is why we want to provide explanations that allow the human agent to understand and take into consideration the context and the limits of algorithms. It is a real challenge to use algorithms to make humans more informed in their decisions, and not the other way around. Algorithms should be a decision aid, not a substitute for human beings.
What are the obstacles associated with the explainability of AI?
FAB: One aspect to be considered when we want to explain an algorithm is cyber security. We must be wary of the potential exploitation of explanations by hackers. There is therefore a triple balance to be found in the development of algorithms: performance, explainability and security.
Is this also an issue of industrial property protection?
WM: Yes, there is also the aspect of protecting business secrets: some developers may be reluctant to discuss their algorithms for fear of being copied. Another counterpart to this is the manipulation of scores: if individuals understand how a ranking algorithm, such as Google’s, works, then it would be possible for them to manipulate their position in the ranking. Manipulation is an important issue not only for search engines, but also for fraud or cyber-attack detection algorithms.
How do you think AI should evolve?
FAB: There are many issues associated with AI. In the coming decades, we will have to move away from the single objective of algorithm performance to multiple additional objectives such as explainability, but also equitability and reliability. All of these objectives will redefine machine learning. Algorithms have spread rapidly and have enormous effects on the evolution of society, but they are very rarely accompanied by instructions for their use. A set of adapted explanations must go hand in hand with their implementation in order to be able to control their place in society.
https://imtech-test.imt.fr/wp-content/uploads/2021/02/joshua-sortino-LqKhnDzSF-8-unsplash-scaled.jpg17102560I'MTechI'MTech2021-04-07 16:16:562021-08-24 10:06:34Shedding some light on black box algorithms
The RAMP-UP Seed project is one of 9 new projects to have been selected by the German-French Academy for the Industry of the Future as part of the “Resilience and Sustainability for the Industry of the Future” call for projects. It focuses on helping companies adapt their production capacities to respond to crisis situations. The project relies on two main areas of expertise to address this issue: ramp-up management and artificial intelligence (AI). Khaled Medini and Olivier Boissier, researchers at Mines Saint-Étienne,[1] a partner of the project, present the issues.
Can you describe the context for the RAMP-UP Seed project?
Khaled Medini The RAMP-UP Seed project is one of 9 new projects to have been selected by the German-French Academy for the Industry of the Future (GFA) for the call for projects on the sustainability and resiliency of companies in the industry of the future. This project is jointly conducted by Mines Saint-Étienne and TUM (Technische Universität München), and is a continuation of work carried out on diversity management, ramp-up management, and multi-agent systems at Institut Fayol related to the industry of the future.
What is the project’s goal?
KM The health crisis has highlighted the limitations of current industrial models when it comes to providing a quick response to market demands in terms of quality and quantity, and production constraints related to crisis situations. Ramp-up and ramp-down management is a key to meeting these challenges. The goal of RAMP-UP Seed is to establish a road map for developing a tool-based methodology in order to increase companies’ sustainability and resilience specifically by targeting the adaptation phase and production facilities.
How do you plan to achieve this? What are the scientific obstacles you must overcome?
Olivier Boissier The project addresses issues related to the topics of production systems and artificial intelligence. The goal is to remedy a lack of methodology guides and tools for strengthening companies’ sustainability and resilience. Two main actions will be prioritized for this purpose during the initial seed stage:
An analysis of existing approaches and identification with industrial stakeholders of needs and use cases, which will be conducted jointly with two partners;
Development of a proposal for a collaborative project involving Franco-German academic and industrial partners in order to respond to European calls for projects.
From an operational standpoint, work meetings and workshops are held regularly with teams from Mines Saint-Étienne and the TUM in a spirit of collaboration.
Who are the partners involved in this project and what are their respective roles?
KM We started RAMP-UP Seed in partnership with the TUM Institute of Automation and Information Systems with a focus on two main areas: ramp-up management and artificial intelligence. Expertise from the Territoire and IT’M Factory platforms from Institut Henri Fayol, and TUM platforms will be used to develop this dynamic further.
Who will benefit from the methods and tools developed by RAMP-UP Seed?
OB The purpose of the multi-agent optimization and simulation tools and industrial management tools to be developed through this project is to provide decision-making tools for exploring, testing and better managing ramp-up in the manufacturing and service sectors. Special attention will also be given to the health crisis, with a focus on the health sector.
What are the next big steps for the project?
KM RAMP-UP Seed is a seed project. In addition to analyzing current trends, one of the key goals is to develop joint responses to calls for projects in the fields of artificial intelligence and industrial management.
https://imtech-test.imt.fr/wp-content/uploads/2020/12/Une_330x660.png8001600I'MTechI'MTech2021-03-02 14:16:462021-03-02 14:40:59Supporting companies in the midst of crisis