Technology that decrypts the way our brain works
Different techniques are used to study of the functioning of our brain, including electroencephalography, magnetoencephalography, functional MRI and spectroscopy. The signals are processed and interpreted to analyze the cognitive processes in question. EEG and MRI are the two most commonly used techniques in cognitive science. Their performances offer hope and but also concern. What is the current state of affairs of brain function analysis and what are its limits?
Nesma Houmani is a specialist in electroencephalography (EEG) signal analysis and processing at Télécom SudParis. Neuron activity in the brain generates electrical changes which can be detected on the scalp. These are recorded using a cap fitted with strategically-placed electrodes. The advantages of EEG are that it is not costly, easily accessible and noninvasive for the subjects being studied. However, it generates a complex signal composed of oscillations associated with new baseline brain activity when the patient is awake and at rest, punctual signals linked to activations generated by the test and variable background noise caused, notably, by involuntary movements by the subject.
The level of noise depends, among other things, on the type of electrodes used, whether dry or with gel. While the latter reduces the detection of signals not emitted by brain activity, they take longer to place, may cause allergic reactions and require the patient to thoroughly wash with shampoo after the examination, making it more complicated to carry out these tests outside hospitals. Dry electrodes are being introduced in hospitals, but the signals recorded have a high level of noise.
The researcher at Télécom SudParis uses machine learning and artificial intelligence algorithms to extract EEG markers. “I use information theory combined with statistical learning methods to process EEG time series of a few milliseconds.” Information theory supposes that signals with higher entropy contain more information. In other words, when the probability of an event occurring is low, the signal contains more information and is therefore more likely to be relevant. Nesma Houmani’s work allows the removal of parasite signals from the trace and a more accurate interpretation of the EEG data recorded.
A study published in 2015 showed that this technique allowed better definition of the EEG signal in the detection of Alzheimer’s disease. Statistical modeling allows consideration of the interaction between the different areas of the brain over time. As part of her research on visual attention, Nesma Houmani uses EEG combined with an eye tracking device to determine how a subject engages in and withdraws from a task: “The participants must observe images on a screen and carry out different actions according to the image shown. A camera is used to identify the point of gaze, allowing us to reconstitute eye movements,” she explains. Other teams use EEG for emotional state discrimination or for understanding decision-making mechanisms.
EEG provides useful data because it has a temporal resolution of a few milliseconds. It is often used in applications for brain-machine interfaces, allowing a person’s brain activity to be observed in real time with just a few seconds’ delay. “However, EEG is limited in terms of spatial resolution,” explains Nesma Houmani. This is because the electrodes are, in a sense, placed on the scalp in two dimensions, whereas the folds in the cortex are three-dimensional and activity may come from areas that are further below the surface. In addition, each electrode measures the sum of synchronous activity for a group of neurons.
The most popular tool of the moment: fMRI
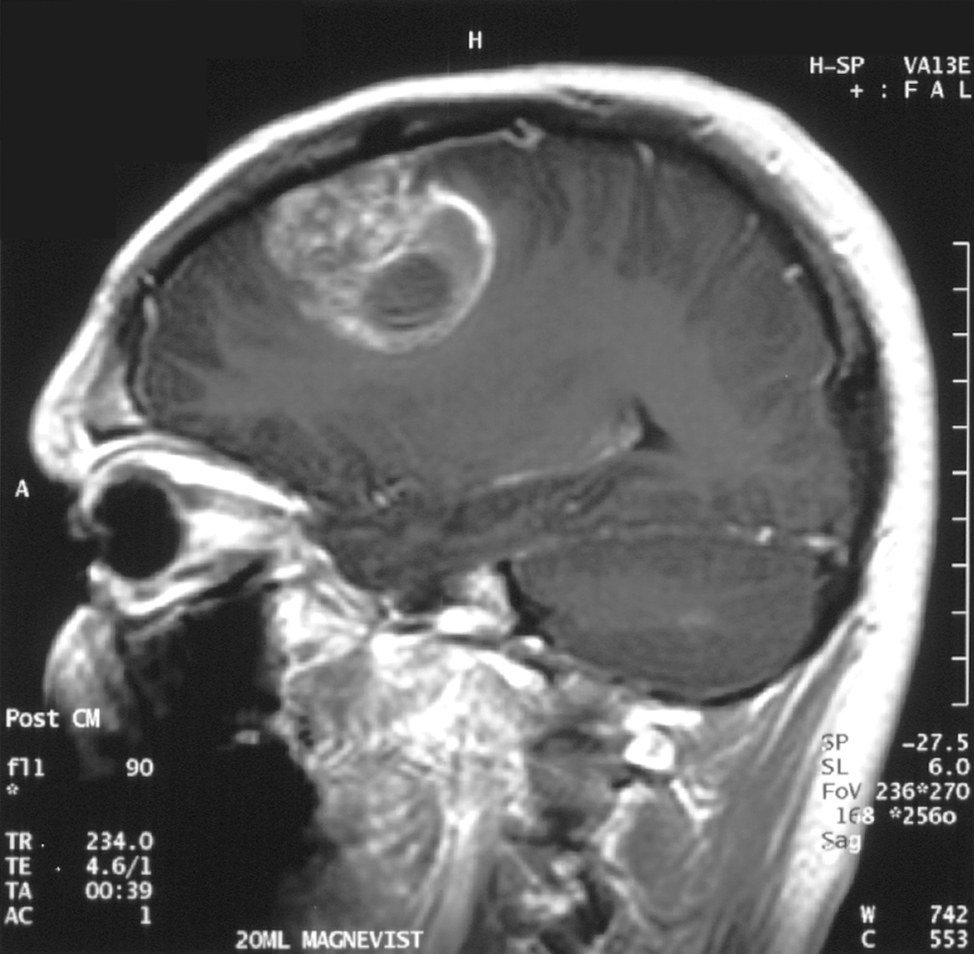
Conversely, functional MRI (fMRI) has excellent spatial resolution but poor temporal resolution. It has been used a lot in recent scientific studies but is costly and access is limited by the number of devices available. Moreover, the level of noise it produces when in operation and the subject’s position lying down in a tube can be stressful for participants. Brain activity is reconstituted in real time by detecting a magnetic signal linked to the amount of blood transferred by micro-vessels at a given moment, which is visualized over 3D anatomical planes. Although activations can be accurately situated, hemodynamic variations occur a few seconds after the stimulus, which explains why the temporal resolution is lower than that of EEG.
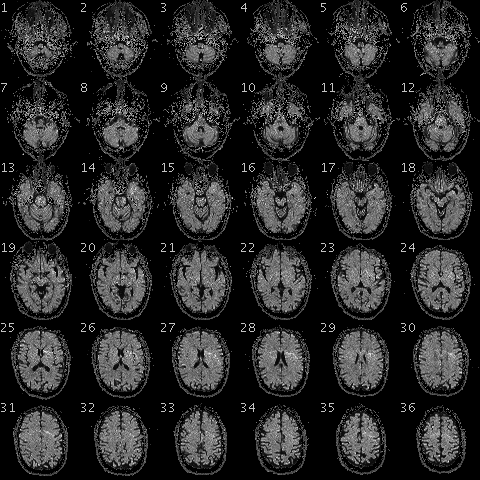
fMRI produces section images of the brain with good spatial resolution but poor temporal resolution.
Nicolas Farrugia has carried out several studies with fMRI and music. He is currently working on applications for machine learning and artificial intelligence in neuroscience at IMT Atlantique. “Two main paradigms are being studied in neuroscience: coding and decoding. The first aims to predict brain activity triggered by a stimulus, while the second aims to identify the stimulus from the activity,” the researcher explains. A study published in 2017 showed the possibilities of fMRI associated with artificial intelligence in decoding. Researchers asked subjects to watch videos in an MRI scanner for several hours. A model was then developed using machine learning, which was able to reconstruct a low-definition image of what the participant saw based on the signals recorded in their visual cortex. fMRI is a particularly interesting technique for studying cognitive mechanisms, and many researchers consider it the key to understanding the human brain, but it nevertheless has its limits.
Reproducibility problems
Research protocol changed recently. Nicolas Farrugia explains: “The majority of publications in cognitive neuroscience use simple statistical models based on functional MRI contrasts by subtracting the activations recorded in the brain for two experimental conditions A and B, such as reading versus rest.” But several problems have led researchers to modify this approach. “Neuroscience is facing a major reproducibility challenge,” admits Nicolas Farrugia. Different limitations have been identified in publications, such as a small workforce, a high level of noise and a separate analysis for each part of the brain, not to mention any interactions or the relative intensity of activation in each area.
“These reproducibility problems are leading researchers to change methods, from an inference technique in which all available data is used to obtain a model that cannot be generalized, to a prediction technique in which the model learns from part of the data and is then tested on the rest.” This approach, which is the basis for machine learning, allows the model’s relevance to be checked in comparison with the actual reality. “Thanks to artificial intelligence, we are seeing the development of computational calculation methods which were not possible with standard statistics. In time, this will allow researchers to predict what type of image or what piece of music the person is thinking of based on their brain activity.”
Unfortunately, there are also reproducibility problems in signal processing with machine learning. The technique, which is based on artificial neural networks, is currently the most popular because it is very effective in multiple applications, but it requires adjusting hundreds of thousands of parameters using optimization methods. Researchers tend to adjust the parameters of the developed model when they evaluate it and repeat it on the same data, thus distorting the generalization of results. The use of machine learning also leads to another problem for signal detection and analysis: the ability to interpret the results. Knowledge of deep learning mechanisms is currently very limited and is a field of research in its own right, so our understanding of how human neurons function could in fact come from our understanding of how deep artificial neurons function. A strange sort of mise en abyme!
Article written by Sarah Balfagon, for I’MTech.