On February 8, 2018, the approval committee for the Digital Fund of the Graduate Schools and Universities Initiative chose four new startups to receive loans for amounts up to €40,000 with a 0% interest rate. Cyrating, which was founded through the ParisTech Entrepreneurs incubator, Galanck and myLabel, both of which were developed through the IMT Starter(Télécom Sud Paris and Télécom École de Management), and WaryMe, created at the IMT Atlantiqueincubator will benefit from these loans to help kickstart their business. Co-financed by Fondation Mines-Télécom, la Caisse des dépôts and Revital’Emploi, this loan program helps startups created through incubators at IMT graduate schools obtain the resources they need to grow. In 2018, the program has set a goal to support 30 startups, for a total of over €560,000.
[one_half]
[box type=”shadow” align=”” class=”” width=””]
Cyrating provides a service for analyzing and rating companies’ cybersecurity performance. It therefore allows them to position themselves in relation to their competitors and identify weaknesses in order to improve their services. Find out more
[/box]
[box type=”shadow” align=”” class=”” width=””]
myLabel is a digital platform where consumers may define their own environmentally-friendly labels and take advantage of associated features, which help the brands and labels present on the platform position their products more effectively.
Galanck is developing a smart backpack for cyclists which is connected to an application. A brake light, signals and vibrators are built into the straps to guide cyclists, making bicycles safer and more visible on the road.
[/box]
[box type=”shadow” align=”” class=”” width=””]
WaryMe has developed a mobile, decentralized alert system to help establishments manage crisis situations, especially intrusions or terror attacks.
[/box]
[/one_half_last]
https://imtech-test.imt.fr/wp-content/uploads/2018/05/MG_3031.jpg13332000I'MTechI'MTech2018-05-23 16:10:212018-05-23 16:21:49New interest-free loans for startups Cyrating, Galanck, myLabel and WaryMe
[dropcap]I[/dropcap]n 2016, for the first time in France, online advertising investment exceeded that of television advertising. Algorithms now play an increasingly significant role in the purchase of advertising space on websites, raising many ethical and legal issues.
Algorithms rise to power
The digital advertising market in France is now estimated at €3.5 billion. Whereas up until now this advertising mainly involved displays on web sites, and the purchase of Google AdWords, the purchase of automated advertising space (called “programmatic buying”) has now emerged. The profiling of internet users is carried out using traces of their web activity, which makes it possible to predict their interest in an ad at any given time. Therefore, thanks to algorithms, it is possible to calculate, in real time, the value of the advertising space on a page the user is viewing.
The use of algorithms has the advantage of displaying banner ads that match our interests, but there are risks involved in their uncontrolled use. The lack of transparency in how these algorithms operate impacts internet users’ behavior without them realizing it. What is more, the algorithms sometimes benefit from exaggerated confidence, yet their results can be discriminatory. This raises the question of algorithms’ neutrality and ethical issues. The study of ethics in this area must be based on an understanding of how we are linked to these new technologies. This involves, on the one hand, how algorithms are covered by law and, on the other hand, the development of the digital advertising ecosystem.
In light of these new challenges, it would be wise to focus on the algorithms themselves, rather than on the data that is processed, by establishing systems capable of testing and controlling them, in order to prevent harmful consequences.
Law and algorithms: reforms in Europe
A new revolution is underway, based on data collection and processing that has reached an unprecedented scale, and stimulates the creation of new products and services. This increase in the amount and diversity of data is explained by the development of connected objects and the empowerment of consumers. Their ability to act has increased with the development of technology: businesses are becoming more and more dependent not only on the data consumers produce, but also on their opinion, and must therefore constantly ensure they maintain a good e-reputation.
In light of this situation, European institutions have begun the process of reforming personal data legislation. The new European General Data Protection Regulation (GDPR) will enter into force in all Member States in May 2018. It imposes increased transparency and the accountability of those who process data, based on a policy of compliance with the law, and it provides for severe penalties. Similarly, it affirms the right to data portability, and those in charge of processing personal data must ensure that their operations comply with personal data protection standards, starting at the design stages for a product or service (privacy by design).
The GDPR strives to implicitly regulate the algorithmic processing of data. We see a trend in the advertising sector: in general, all sites, services and products that use algorithms are careful not to refer to them. They hide the crucial role algorithms play, instead referring to “customization”. However, when there is customization, often there is “algorithmization”.
Legislation ill-suited to digital advertising
Laws pertaining to “traditional” advertising are based on the principle of receiving prior informed consent from individuals before processing their data. However, this concept of data protection is less relevant when it comes to digital advertising. Data collected in the context of traditional marketing often involves objective and relatively predictable information such as name, age, gender, address or marital status. Yet the concept of “data” radically changes when it comes to digital marketing. On social networks, the data is not only basic classification information (age, gender, address), but also includes data from everyday life: what I’m doing, what I’m listening to, etc.
Traces of web activity and individuals’ behavior on social networks make it possible to determine their profile. VisualHunt
This new situation questions the relevance of the distinction between personal and non-personal data. It also raises questions about the relevance of the principle of prior consent. It is often virtually impossible to use an application without accepting to be tracked. Consent therefore becomes mandatory in order to use the technology, and exactly how the data will be used by the data controller is completely unknown. Therefore, the problem is no longer related to prior consent, rather it is the automatic, predictive deductions made by the companies that collect this data.
Algorithms accentuate this trend by multiplying the collection and use of trivial and decontextualized data, likely to be used for specifically profiling individuals, and creating “knowledge” about them based on probabilities rather than certainties about their personal and intimate inclinations. In this situation, rather than examining the data feeding the algorithms, wouldn’t it be more relevant to examine the algorithms that process them and generate new data?
Legal and ethical challenges of online advertising
Influencing consumer choices, subliminal influence, submission that changes the perception of reality: behavioral targeting carries serious risks. Requirements for the accountability, transparency and verifiability of the actions caused by algorithms have become crucial in preventing potential excesses.
This situation calls into question the relationship between law and ethics, which is unfortunately often confused. Laws are established to regulate behavior—what is allowed, forbidden, or required from a legal perspective—whereas ethics refers more broadly to the distinction between good and bad, independent of and beyond any compliance with the law. Ethics applied to algorithmic processing would need to focus on two major principles: transparency, and the establishment of tests to check the algorithms’ results in order to prevent possible damage.
Transparency and accountability of algorithms
The activities of online platforms are essentially based on the selection and classification of information, as well as on offers for goods or services. They design and activate various algorithms that influence consumption behavior and how users think. This customization is sometimes misleading, since it is based on the machine’s concept of how we think. This concept is not based on who we are, but rather on what we have done and looked at. This observation reveals the need for transparency: the people impacted by an algorithm should first of all be informed of the existence of the algorithmic processing, as well as what it implies, the type of data it uses and its end purpose, so that they may file a claim if needs be.
Tests for algorithms?
In advertising, algorithms can lead to a differentiation in the price of a product or service or can even establish typologies of high-risk policyholders in order to calculate the insurance premium based on criteria that is sometimes illegal, by cross-checking “sensitive” information. Not only is the collection and the processing of this data (racial and ethnic origins, political and religious opinions) generally prohibited, the results of these algorithmic methods can be discriminatory. For example, the results of the first international beauty contest based entirely on algorithms led to the selection of only white candidates.
To avoid this type of abuse, urgent steps must be taken to establish tests for the results produced by algorithms. In addition to the legislation and the role played by the protection authorities (CNIL), codes of conduct are also beginning to appear: advertising professionals belonging to the Digital Advertising Alliance (ACD) have introduced a protocol represented by a visible icon next to a targeted ad that explains how it works.
It is in companies’ interests to adopt more ethical behavior in order to maintain a good reputation, and hence a competitive advantage. Internet users are weary of advertising deemed too intrusive. If the ultimate goal of advertising is to better anticipate our needs to “consume better”, it must occur in an environment that complies with legislation and is responsible and ethical. This could be a vector for a new industrial revolution that is mindful of fundamental rights and freedoms, in which citizens are invited to take their rightful place and take ownership of their data.
Four research institutions, including Télécom ParisTech and Télécom SudParis, are embarking on a joint research initiative focused on the blockchain. Along with INRIA and the Institute for Technological Research (IRT) SystemX, this scientific task force will take on the challenge of integrating the blockchain into industrial processes. The six focus areas of this research initiative called Blockchain Advanced Research & Technologies (BART) are scaling-up, security, data confidentiality, architecture, monitoring and business models. Gérard Memmi, head of the IT & Networks Department at Télécom ParisTech explains the objectives of this initiative, launched on 6 March 2018.
Why create a joint research initiative on the blockchain?
Gérard Memmi: The blockchain is often seen as a mature technology. In some ways it is, since it is based on scientific findings that have been known for 20 or 30 years—such as Merkle trees and the Byzantine generals problem. Yet this is not enough to make the blockchain the revolutionary technology that everyone expects it to become. Constant research must be carried out behind the scenes to ensure greater security, to scale the technology up for use by companies, and to make it compatible with current and future information systems. For example, the current proof-of-work system required for maintaining the blocks is incompatible with industrial performance requirements: it requires too many IT resources and too much time and energy. There are real scientific challenges ahead!
What will each of the different partners of the Blockchain Advanced Research & Technologies (BART) contribute?
GM: We expect INRIA to provide research in the areas of formal verification, theoretical computer science, cryptography… What I believe they expect of us is related to applications: connections with telecommunications protocols, the development of IT architectures, cybersecurity, scaling-up… However, I hope there will be a lot of interaction between the researchers of the different disciplines I just mentioned. Through the involvement of IMT, we will also be able to use the TeraLab platform. SystemX contributes valuable connections with manufacturers and plans to use scientific findings to fuel work situated downstream in companies’ industrialization processes. That is their role as an Institute for Technological Research.
What is the goal of the Blockchain Advanced Research & Technologies (BART) initiative?
GM: In creating BART, we hope to form a multidisciplinary research team that will be a blockchain benchmark in France. We have the means to accomplish this partly because we have been working on this topic for a long time. Three years ago, we launched one of the first theses on the blockchain in France as part of the joint SEIDO laboratory with EDF, at a time when no one was talking about this technology. SystemX launched research projects involving industrial partners as early as 2016, specifically through the Blockchain for Smart Transactions (BST) project. We have therefore been able to begin creating a network of high-level scientific and industrial relationships.
Does this mean BART is anchored in dynamics that already existed?
GM: Yes, we are in the active launch phase. The signing of the framework agreement is not simply a matter of policy, it reflects real concrete actions. Personally, I see the BART initiative as part of a unified whole. For example, one of the PhD students funded by BART will go to Munich Technical University (TUM) to work on their blockchain platform. This cooperation really makes sense, since IMT and TUM have founded the Franco-German Industry of the Future Academy. In addition, as part of this alliance we are developing a Franco-German project called HyBlockArch devoted to blockchain architecture for industry. Although institutional connections do not always exist between these different entities, the work of each one is recognized by the others and contributes to the whole. This is also a great principle of international research: we come together with a common purpose and take advantage of all the possible synergies to make the greatest possible impact on science and society.
https://imtech-test.imt.fr/wp-content/uploads/2018/05/Visuel_Une.jpg8531280I'MTechI'MTech2018-05-09 15:06:312019-02-19 09:54:57Introducing BART, the Blockchain’s French Scientific Alliance
Over the course of three months, TeraLab was involved in two European H2020 projects on the industry of the future: MIDIH and BOOST 4.0. This confirms the role played by TeraLab—IMT’s big data and artificial intelligence platform—as a trusted third party and facilitator of experimentation. TeraLab created a safe place for these projects, far from competitive markets, where industry stakeholders could accept to share their data.
“Data sharing is the key to opening up research in Europe,” says Anne-Sophie Taillandier. According to the director of TeraLab—IMT’s big data and AI platform—a major challenge exists in the sharing of data between industrial players and academics. For SMEs and research institutions, having access to industrial data means working on real economic and professional problems. This is an excellent opportunity for accelerating prototypes and proofs of concept and removing scientific barriers. Yet for industrial stakeholders, the owners of the data, this sharing must not compromise security. “They want guarantees,” says the Director, who was ranked last February among the top 20 individuals driving AI in France by French business magazine L’Usine Nouvelle.
It is in this perspective of offering guarantees that the TeraLab platform joined the consortia of two European projects from the H2020 program: BOOST 4.0 (January 2018) and MIDIH (October 2017). The first project brought together 50 industrial and academic partners, including 13 pilot plants in Europe. The project is intended to create a replicable model of a smart industry in which data would form the basis for reflections on operational efficiency, user experience and even the creation of a business model. This level of ambition requires significant work on interoperability, security and data sharing. “But it is clear that Volvo and Volkswagen, both members of the Boost 4.0 consortium, will not provide access to their data without first experiencing a certain level of trust,” explains Anne-Sophie Taillandier. A platform like TeraLab allows companies to benefit from technological and legal advantages that make it a safe workspace.
The MIDIH project, on the other hand, seeks to provide companies with the technological, financial and material resources required for developing innovative solutions for the industry of the future through sub-grants. “In practical terms, the H2020 project will finance calls for projects on logistics, predictive maintenance and steel cutting and will offer support to successful applicants,” the TeraLab director explains. The companies selected through these calls for projects will be able to develop proofs of concept for solving industrial problems experienced by SMEs. They use platforms like TeraLab to accomplish this, since they “provide the assurance of the sovereignty and cybersecurity of the data the prototypes will produce.” For these companies, the ability to use an independent platform of this magnitude is truly beneficial in accelerating their projects.
A platform recognized at European level
TeraLab’s involvement in these projects is also due to the recognition it has earned at European level. In 2016, the Big Data Value Association (BDVA) granted TeraLab its Silver i-Space Label. This recognition is far from trivial, since BVDA leads the European private-public partnership on big data. BOOST 4.0 is the result of reflection carried out by this same partnership, which works to advance the major issues that industrial stakeholders have presented to the European Commission. “The context of the European Commission is incredible because many different stakeholders gravitate there, but within a given theme, everyone knows each other,” Anne-Sophie Taillandier admits. “The Silver i-Space Label awarded in 2016 provided both recognition from big data stakeholders and strategic positioning within this environment.”
In Europe, few platforms like TeraLab exist. Only ten hold the Silver i-Space Label—the highest level—held by TeraLab, the only French awardee of this recognition. It therefore represents a valuable gateway to involvement in European projects. “It legitimizes our responses to calls for bids such as these two projects on industry 4.0,” says the Director of the platform. The industry of the future is a topic TeraLab had already worked on before joining the MIDIH and BOOST 4.0 projects. “One of our strengths, which was recognized by both consortia, was our ability to develop a community of researchers and innovators on this subject,” says Anne-Sophie Taillandier. She also reminds us that the industry is not the only theme TeraLab has explored in the context of in-depth projects. This offers good prospects for TeraLab to be involved in other European projects on other specialized areas, such as healthcare.
https://imtech-test.imt.fr/wp-content/uploads/2018/05/Une_Teralab_sanctuaire_europeen.jpg10801440I'MTechI'MTech2018-05-02 15:00:422019-10-14 15:09:39TeraLab, a European data sanctuary
Thanks to its generous sponsors, Fondation Mines-Télécom was able to fund 22 interest-free loans in 2017 for entrepreneurs supported by IMT incubators. A total of €440,000 was awarded to 12 startups. In 2018, the Foundation intends to take its support for entrepreneurship a step further by awarding 30 interest-free loans.
Promising figures
To support the development of startups at IMT incubators, Fondation Mines-Télécom awards interest-free loans to entrepreneurs through the Graduate Schools and Universities Initiative. In 2017, twelve startups selected by the Foundation’s corporate partners benefitted from an interest-free loan. A total of €2.3 million in loans has been awarded since 2008, with an attrition rate of under 8%.
These no-collateral loans ranging between €20,000 and €40,000 help leverage funding for projects. Startups that received these loans have raised considerable funds this year, especially fintech Pledg (€1.2 million) and Seaver, which specializes in the IoT (Internet of Things) for the equine industry. The fact that many of these startups take part in the Las Vegas CES every year also attests to their strong performance. The objective for 2018 is to award interest-free loans to 30 new entrepreneurs to support 15 projects, representing a total of more than €560,000. To help achieve this goal, program partners Caisse des Dépôts and Revital’emploi are renewing their support.
Innovative services and products in the field of digital technology
The startups supported by these loans respond to different needs in the field of digital technology and take advantage of opportunities provided by big data. One such startup, Predictice, provides analytic solutions for court decisions designed for legal professionals.
Many of the startups specialize in connected objects. HEROZ, for example, is a connected accessory that protects smartphones from being stolen, lost, forgotten and also protects against intrusion. Keepen offers an autonomous alarm that everyone can access which is both more convenient and more reliable than current systems.
They also provide innovative services and create new user experiences. ThingType provides an online service for electronic design and creation that makes prototyping simple, easy and affordable, while Bruce, a digital and mobile temporary employment agency, helps businesses meet their needs for temporary employment.
Find out more about the interest-free loan program
Nearly 100 startups and spinoffs are created through the IMT incubator network every year. This is why Fondation Mines-Télécom finances a portion of the Digital Fund of the Graduate Schools & Universities Initiative, part of the Initiative France network, which aims to foster the development of new businesses at graduate schools, universities and research laboratories in France.
The interest-free loans play a key role in the development of startups that strive to expand rapidly, both in France and internationally. The loans provide the project with legitimacy, are accompanied by the incubators’ technical expertise and help leverage funding for startup costs. These loans for an amount of up to €40,000 have a one-year grace period and must then be repaid within five years. Repayments are in turn used to provide funding for loans for other entrepreneurs.
https://imtech-test.imt.fr/wp-content/uploads/2018/01/Visuel_Une-7.jpg8801333I'MTechI'MTech2018-04-27 10:32:442018-05-02 17:21:2212 startups supported with interest-free loans in 2017
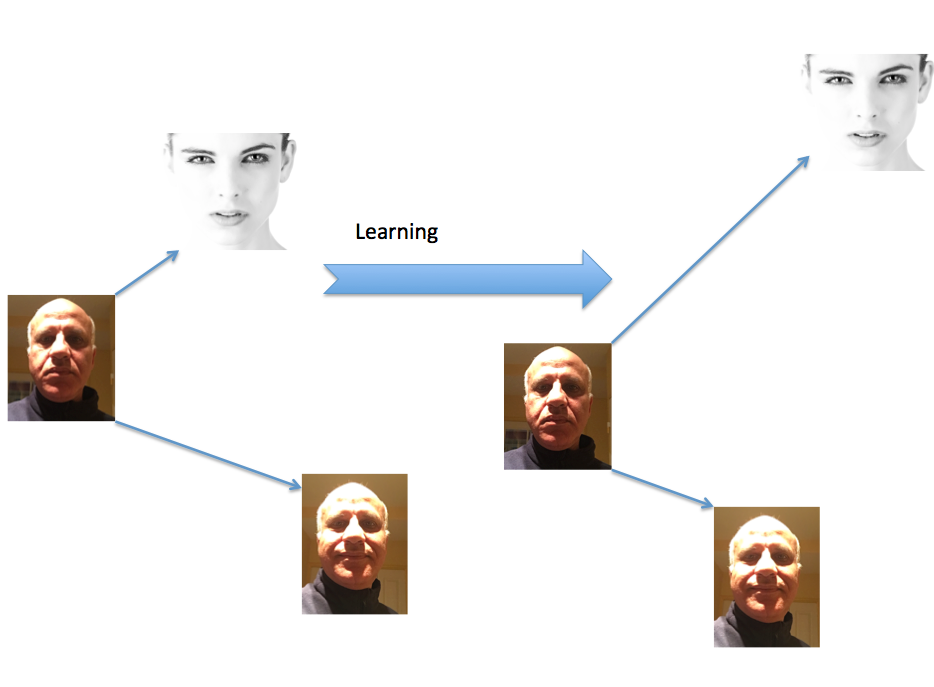
[dropcap]W[/dropcap]elcome to the new era: that of facial biometrics. The launch of the iPhone X, a smartphone featuring Face ID facial recognition, demonstrated that this technology has now reached full maturity. This became possible with the introduction of miniature 3D sensors with high-level computing power, combined with extremely efficient learning algorithms such as deep learning.
But what is facial recognition? It means identifying that two faces are identical despite changes caused by lighting conditions, pose and facial expressions. Generally speaking, this means finding distances within the face that can be used to identify any changes to the face.
Figure showing the same face in different shooting conditions and lighting changes.
In 2014, researchers from Facebook published an article called “DeepFace: Closing the Gap to Human-Level Performance in Face Verification”. To prevent the problems caused by changes in pose, a step was introduced to align the 2D face to a 3D model of the face. The next step involved a deep learning process using a network of artificial neurons consisting of 120 million connections. The learning set was composed of 4.4 million faces of celebrities. The network of neurons was trained to recognize the variances in the faces. The algorithm made it possible to determine if two photographed faces belonged to the same person with a specified accuracy of 97.35%.
In 2015, researchers from Google published an article entitled “FaceNet: A Unified Embedding for Face Recognition and Clustering”. They showed that they were able to achieve a recognition rate of 99.63% using a database of 2D faces captured in an uncontrolled environment. To accomplish this, the authors proposed the use of a neural network consisting of eleven convolutional layers and three connected layers. The idea was to ensure that an image of a specific person would be closer to all the other images of that same person (referred to as positive) than to the images of other people (referred to as negative). The learning was carried out using a database of 200 million face images from 8 million people.
During the training, the learned similarities allowed the images showing the same faces to come closer together, and those showing different faces moved farther apart in relation to a specific metric.
However, the DeepFace and FaceNet experiments were both based on private databases that are not available to the scientific community. A team from the University of Oxford proposed to collect data from the web and has established a database of 2.6 million faces from 2,622 people and has proposed a network architecture called VGG-face consisting of 16 convolutional layers and 3 fully connected layers. Today this architecture is widely used by the computer vision community.
Yet the face is not only a 2D image; it is also a three-dimensional image. Facial biometrics can be used because 3D scanning technologies can scan faces. The major advantage of using 3D in this context is that the facial recognition algorithms are resistant to changes in lighting and pose. Recent work published in 2013 by our team at IMT Lille Douai in the journal IEEE TPAMI, “3D face recognition under expressions, occlusions, and pose variations” showed the advantage of this process. In this article, we proposed to compare two 3D faces by comparing two sets of curves that locally represent the shape of a 3D face. We obtained a recognition rate of 97% (using the testing framework Face Recognition Grand Challenge). The results obtained from several international tests reveal the advantages of 3D faces in facial biometrics systems.
Example of 3D faces captured by the Minolta scanner using laser technology.
Now let us get back to the iPhone X and its 3D technology for facial recognition. A feat made possible by the introduction of miniature 3D sensors on the front of the device: a projector sends 30,000 invisible points onto the user’s face, which are used to create a 3D model of the face. According to Apple, Face ID cannot be fooled by a mere photograph of a face, since the recognition is achieved with a 3D sensor that measures depth.
https://imtech-test.imt.fr/wp-content/uploads/2018/04/Visuel_Une-3.jpg8601300I'MTechI'MTech2018-04-25 15:24:062018-04-25 17:09:38Facial biometrics: How smartphones can recognize us
In the near future, watermarking data could be the best traceability technique in the healthcare domain. It involves hidding information into medical images with the aim at reinforcing data security for patients and healthcare professionals. After being developed for nearly ten years in the laboratories of IMT Atlantique and Medecom, watermarking has now reached a level of maturity that allows its integration into professional products. Yet it still must be approved by standardization bodies.
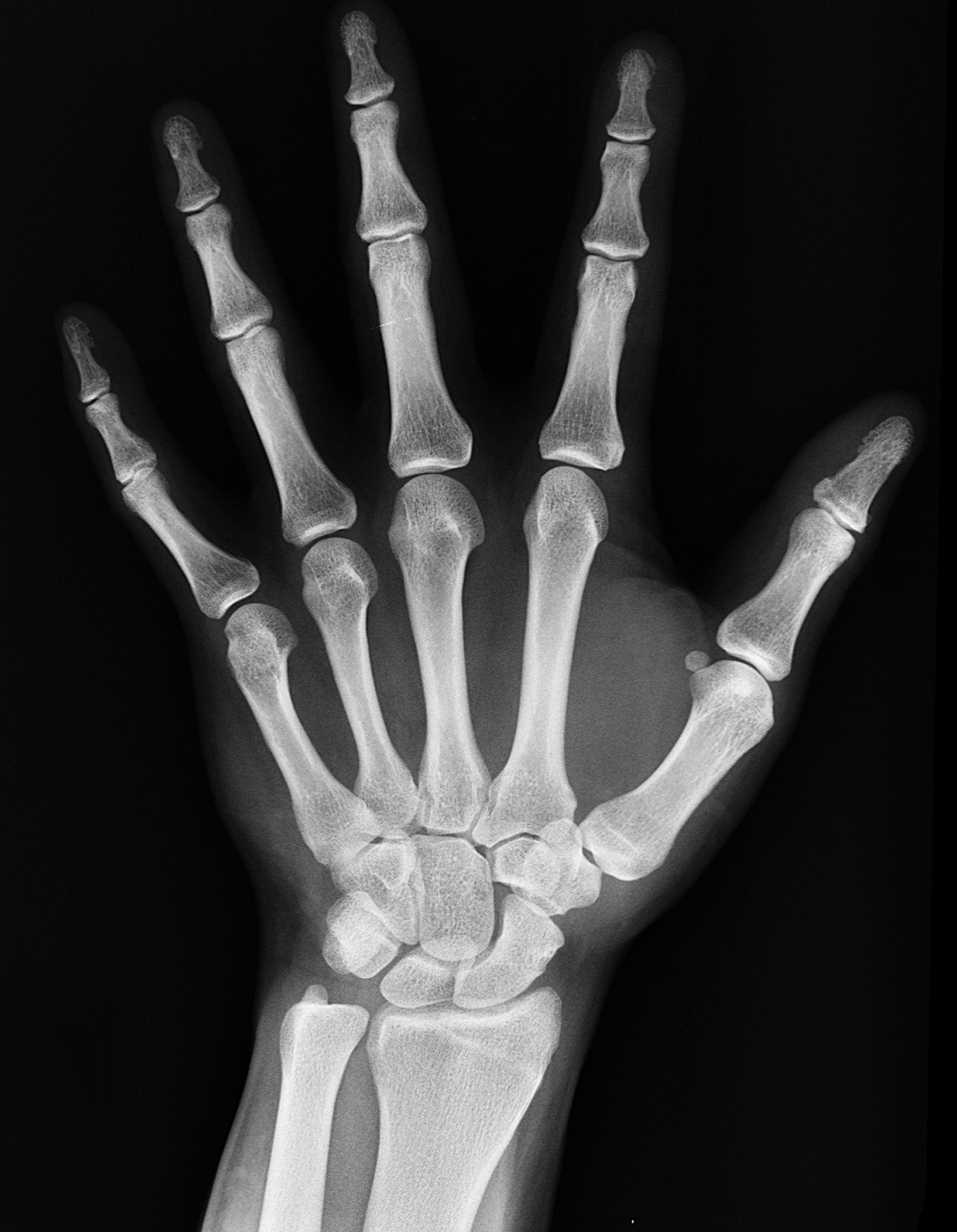
Are you sure that is really your body on the latest X-ray from your medical exam? The question may seem absurd, yet it is crucial that you, your doctor and the radiologist can all answer this question with a resounding “yes”. To ensure this level of certainty, healthcare professionals must rely on the latest technological advances. This is a matter of ensuring the right patient gets the right diagnosis—no one wants an X-ray of their lungs to be switched with one from a chain-smoker!
To ensure an X-ray is correctly associated with the patient and to return a lost X-ray to its rightful owner, the name printed on the X-ray film is not sufficient. An ill-intentioned individual or an administrative error could cause the unfortunate exchange of two patients’ images. Medecom and researchers from IMT Atlantique, part of the Télécom & Société Numérique Carnot Institute, have been working on a more secure system based on the watermarking. For over ten years the two entities have been collaborating on this technology and four years ago they inaugurated SePEMeD, a joint laboratory focused on this area, with support from the French National Agency for Research (ANR). Since then, the maturity and viability of the watermark technology have become increasingly convincing.
A Secret Message
“The watermark draws on the principle of steganography, the art of hidden writing, which is almost as old as cryptography,” explains Gouenou Coatrieux, a researcher in imagery and information processing at IMT Atlantique. “In the case of X-rays, we change some pixels in the image to hide a message and leave an invisible mark,” he continues (see box below). The value of the watermark is that the protection is independent from the storage format. The X-ray can therefore be exchanged between departments and hospitals, each with its own unique system for processing X-ray images, yet this will not affect the watermark, which will continue to contain the information related to the patient.
[box type=”info” align=”” class=”” width=””]
The watermark: a message hidden in the pixels
The secret to watermarking X-rays is in the pixels, which can be encoded in 8, 16 or 32 bits. If a pixel is encoded in 8 bits, this means its color is indicated by a series of 8 bits—a bit is a 0 or 1 in the binary code. There are 256 possible 8-bit combinations: 00000000, 00000001, etc. There are therefore 256 possible colors for a pixel encoded in 8 bits, or 256 different shades of gray for a pixel in a black and white image.
Watermarking an image involves modifying certain pixels by changing one of their bits. This means the color, or shade of gray, is altered. To prevent this from being noticeable on the X-ray, the bit containing the least amount of information—the one located at the end of the 8-bit sequence—is modified. The colors related to bits 00110101 and 00110100 are very similar, whereas those related to bits 00000000 and 10110110 are very different. The more two series of bits are dissimilar, the less similar the colors.
The changed bits in the pixels form a message, which could be a patient’s name or the doctors’ authorization to access the X-ray. To discover which bits bear this message, the X-ray recipient must have the watermark key associated with the medical image. This ensures the secrecy of the message.[/box]
In addition to traceability, watermarking has other advantages. First, it can help detect insurance fraud. If an X-ray is tampered with by an ill-intentioned individual, for example to fake a disease, the secretly watermarked pixels will also be modified, revealing the attempted fraud. Next, the watermark can be added to data that is already encrypted using a method that has been patented by Medecom and IMT Atlantique. It is therefore possible to ensure traceability while maintaining the confidentiality of medical information the image contains. This also makes it possible to write information about certain doctors’ access authorizations directly on the encrypted data.
Moving towards standardization?
While this watermark technology is now mature, it still must pass the test of standardization procedures in order to be implemented in software and the information systems of healthcare professionals. “Our goal now is to show that altering the image with the watermark does not have any effect on the quality of the image and the doctors’ diagnostic capacity,” says Michel Cozic, R&D director at Medecom. The SePEMeD team is therefore working to conduct qualitative studies on watermarked data with physicians.
At the same time, they must convince certain healthcare professionals of the value of watermarking. The protection of personal data, and medical data in particular, is not always viewed the same way throughout the healthcare world. “In the hospital environment, professionals tend to believe that the environment is necessarily secure, which is not always the case,” Michel Cozic explains. In France, and in Europe in general, attitudes about data security are changing. The new General Data Protection Regulation (GDPR) established by the European Commission is proof of this. However, it will be some time before the entire medical community systematically takes data protection into account.
Ten years of research… and ten more to come?
Since there is still a long way to go before healthcare professionals begin using watermarks, the SePEMeD story is not over yet. Founded in 2014 to solidify the collaboration between IMT Atlantique and Medecom, which has lasted over ten years, SePEMeD was originally intended to run only three years. However, following the success of the research which led to promising applications, this first joint laboratory accredited by the ANR on data security will continue its work until at least 2020. Beyond data traceability, SePEMeD is also seeking to improve the security of remotely processed encrypted images in cloud storage.
“We update our focus areas based on our results,” Gouenou Coatrieux notes, explaining why the SePEMeD laboratory has been extended. Michel Cozic agrees: “We are currently focusing our research on issues related to browsers’ access to data, and the integration of watermarking modules in existing products used by professionals.” The compatibility of algorithms with healthcare institutions’ computer configurations and systems will be a major issue involved in the adoption of this technology. Last but not least: ease of use. “No one wants to have to enter passwords in the software,” observes Medecom’s R&D Director. We must therefore succeed in integrating watermarking as a security solution that is straightforward for doctors.
[divider style=”normal” top=”20″ bottom=”20″]
The benefit of collaborating with IMT Atlantique: “The human aspect”
Michel Cozic
One of Télécom & Société Numérique Carnot Institute’s objectives is to professionalize the relationships between companies and researchers. Michel Cozic, Medecom’s R&D Director shares his experience: “There is also a human aspect to these collaborations. Our exchanges with IMT Atlantique go very smoothly, we understand each other. On both sides we accept our differences, constraints and we compromise. We come from two different environments and this means we must have discussions. There must be an atmosphere of trust, a good relationship and a common understanding of the objectives. This is what we have been able to accomplish through the SePEMeD laboratory.”
[divider style=”normal” top=”20″ bottom=”20″]
[box type=”shadow” align=”” class=”” width=””]
The TSN Carnot institute, a guarantee of excellence in partnership-based research since 2006
Having first received the Carnot label in 2006, the Télécom & Société numérique Carnot institute is the first national “Information and Communication Science and Technology” Carnot institute. Home to over 2,000 researchers, it is focused on the technical, economic and social implications of the digital transition. In 2016, the Carnot label was renewed for the second consecutive time, demonstrating the quality of the innovations produced through the collaborations between researchers and companies.
The institute encompasses Télécom ParisTech, IMT Atlantique, Télécom SudParis, Télécom École de Management, Eurecom, Télécom Physique Strasbourg and Télécom Saint-Étienne, École Polytechnique (Lix and CMAP laboratories), Strate École de Design and Femto Engineering.
[/box]
https://imtech-test.imt.fr/wp-content/uploads/2018/04/main-radio.jpg16041246I'MTechI'MTech2018-04-24 11:17:482018-10-09 14:55:27Watermarking: a step closer to secure health data
Anonymization is still sometimes criticized as a practice that supposedly makes data worthless, as it deletes important information. The CNIL decided to prove the contrary through the Cabanon project conducted in 2017. It received assistance from the IMT big data platform, TeraLab, for anonymizing the data of New York taxis and showing the possibility of creating a transportation service.
On 10 March 2014, an image published on Twitter by the New York taxi commission sparked Chris Whong’s curiosity. It wasn’t the information on the vehicle occupancy rate during rush hour that caught the young urban planner’s interest. Rather, what caught his eye was the source of the data, cited at the bottom, that had allowed New York City’s Taxi and Limousine Commission (NYC TLC) to create the image. Through a tweet comment, he joined another Twitter user, Ben Wellington, in asking if the raw data was available. What ensued was a series of exchanges that enabled Chris Whong to retrieve the dataset through a process that is tedious, yet accessible to anyone with enough determination to cut through all the red tape. Once he had the data in his possession, he put it online. This allowed Vijay Pandurangan, a computer engineer, to demonstrate that the identity of the drivers, customers, and their addresses could all be found using the information stored on the taxi logs.
Problems in anonymizing open datasets are not new. They were not even new in 2014 when the story emerged about NYC TLC data. Yet this type of case still persists. One of the reasons is that anonymized datasets are deemed less useful than their unfiltered counterparts. Removing any possibility of tracing the identity would amount to deleting the information. In the case of the New York taxis, for example, this would mean limiting the information on the taxis’ location to geographical areas, rather than indicating the coordinates to the nearest meter. For service creators who want to build applications, and data managers who want the data to be used as effectively as possible, anonymizing means losing value.
As a fervent advocate for the protection of personal data, the French National Commission for Information Technology and Civil Liberties (CNIL) decided to confront this misconception. The Cabanon project, led by the CNIL laboratory of digital innovation (LINC) in 2017, took on the challenge of anonymizing the NYC TLC dataset and using specific scenarios for creating new services. “There are several ways to anonymize data, but there is no miracle solution that fits every purpose,” warns Vincent Toubiana, in charge of anonymizing the datasets for the project, which has since transferred from the CNIL to the ARCEP. The Cabanon team therefore had to think of a dedicated solution.
Spatial and temporal degradation
First step: the GPS coordinates were replaced by the ZCTA code, the U.S. equivalent of postal codes in France. This is the method chosen by Uber to ensure personal data security. This operation degrades the spatial data; it drowns the taxi’s departure and arrival positions in areas composed of several city blocks. However, this may prove insufficient in truly ensuring the anonymity of the customers and drivers. At certain times during the night, sometimes only one taxi made a trip from one area of the city to another. Even if the GPS positions are erased, it is still possible to link the geographical position and identity.
“Therefore, in addition to the spatial degradation, we had to introduce a temporal degradation,” Vincent Toubiana explains. The time slots are adapted to avoid the single customer problem. “In each departure and arrival area, we look at all the people who take a taxi in time slots of 5, 15, 30 and 60 minutes,” he continues. In the data set, the time calibration is adjusted so that no time slot has fewer than ten people. If, despite these precautions, a single customer is within the largest time slot of 60 minutes, the data is simply deleted. According to Vincent Toubiana, “the goal is to find the best mathematical compromise for keeping a maximum amount of data with the smallest possible time intervals.”
In the 2013 data used by the CNIL, the same data made public by Chris Whong, NYC TLC made over 130 million trips. The double degradation operations therefore demanded significant computing resources. The handling of the data to be processed using different temporal and spatial slicing required assistance from TeraLab, IMT’s big data platform. “It was essential for us to work with TeraLab in order to query the database to see the 5-minute intervals, or to test the minimum number of people we could group together,” Vincent Toubiana explains.
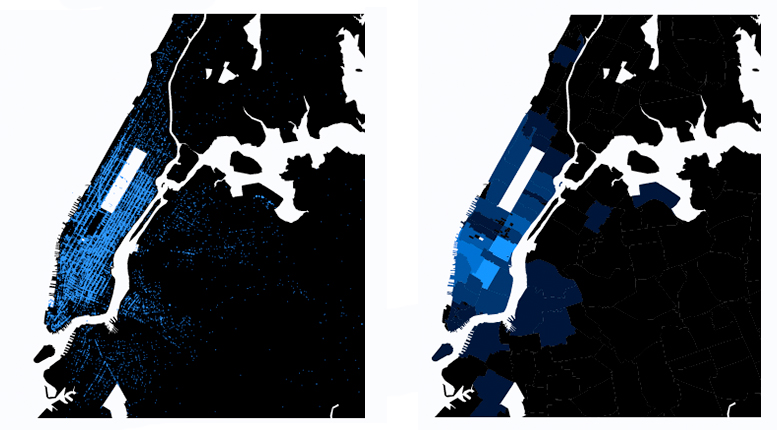
Once the dataset has been anonymized in this way, it must be proven useful. To facilitate its reading, a data visualization in the form of a choropleth map was produced—a geographical representation associating a color with each area based on the amount of trips. “The visual offers a better understanding of the differences between anonymized data and that which is not, and facilitates the analysis and narration of this data,” says Estelle Hary, designer at the CNIL who produced the data visualization.
To the left: a map representing the trips using non-anonymized data. To the right: choropleth map representing the journeys with a granularity that ensures anonymity.
Based on this map, they began reflection on the kinds of services that could be created using anonymized data. The map helped identify points in Brooklyn where people order taxis to complete their journey home. “We started thinking about the idea of a private transportation network that would complement public transport in New York,” says Estelle Hary. Since they would be cheaper than taxis, this private public transport could cover areas neglected by buses. “This is a typical example of a viable service that anonymized data can be used to create,” she continues. In this case, the information that was lost to protect the personal data had no impact. The processed data set is just as effective. And this is only one example of a potential use. “By linking anonymized datasets with other public data, the possibilities are multiplied,” the designer explains. In other words, the value of an open dataset depends on our capacity for creativity.
There will certainly always be cases in which the degradation of raw data limits the creation of a service. This is the case for more personalized services. But perhaps anonymity should be seen, not as a binary value, but as a gradient. Instead of seeing anonymity as a characteristic that is present or absent from datasets, wouldn’t it be more appropriate to consider several accessible degrees of anonymity according to the exposure of the data set and the control over the use? That is what is the CNIL proposed in the conclusion of the Cabanon project. The data could be publicly accessible in fully anonymized form. In addition, the same dataset could be accessible in versions that are less and less anonymized, with, in exchange, a more significant level of control over the use.
[box type=”info” align=”” class=”” width=””]
TeraLab, big data service for researchers
Teralab is a big data and artificial intelligence platform serving research, innovation and education. It is led by Institut Mines-Télécom (IMT) and the Group of National Schools of Economics and Statistics (GENES). Teralab was founded in 2014 through a call for projects by the Investments for the Future program called “Cloud Computing and Big Data”. The goal of the platform is to aggregate the demand for software and infrastructure for projects involving large volumes of data. It also offers security and sovereignty, enabling stakeholders to entrust their data to the researchers with confidence. [/box]
https://imtech-test.imt.fr/wp-content/uploads/2018/01/Une-cabanon_plus_claire.jpg13141806I'MTechI'MTech2018-04-20 16:02:432018-04-20 16:16:07Is anonymized data of any value?
Our electronic and computing devices are becoming smaller, more adapted to our needs, and closer to us physically. From the very first heavy, stationary and complex computers, we have moved on to our smartphones, ever at the ready. What innovations can we next expect? Éric Lecolinet, researcher in human-machine interactions at Télécom ParisTech, answers our questions about this rapidly changing field.
How do you define human-machine interactions?
Human-machine interactions refer to all the interactions between humans and electronic or computing devices, as well as the interactions between humans via these devices. This includes everything from desktop computers and smartphones to airplane cockpits and industrial machines! The study of these interactions is very broad, with applications in virtually every field. It involves developing machines capable of representing data that the user can easily interpret and allowing the user to interact intuitively with this data.
In human-machine interactions, we distinguish between output data, which is sent by the machine to the human, and input data, which is sent from the human to the machine. In general, the output data is visual, since it is sent via screens, but it can also be auditory or even tactile, using vibrations for example. Input data is generally sent using a keyboard and mouse, but we can also communicate with machines through gestures, voice and touch!
The study of human-machine interactions is a multidisciplinary field. It involves IT disciplines (software engineering, machine learning, signal and image processing), as well as social science disciplines (cognitive psychology, ergonomics, sociology). Finally, design, graphic arts, hardware, and new materials are also very important areas involved in developing new interfaces.
How have human-machine interactions changed?
Let’s go back a few years to the 1950s. At that time, computer devices were computing centers: stationary, bulky machines located in specialized laboratories. The humans were the ones who adapted to the computers: you had to learn their language and become an expert in the field if you wanted to interact with them.
The next step was the personal computer, the Macintosh, in 1984, following work by Xerox Parc in the 1970s. What a shock! The computer belonged to you, was in your office and home. First the desktop PC was developed, followed by the laptop that you could take with you anywhere: here the idea of ownership emerged, and machines become mobile. And finally, these first personal computers were made to facilitate interaction. It was no longer the user’s job to learn the machine’s language. The machine itself facilitated the interaction, particularly with the WIMP (Window Icon Menu Pointer) model, the desktop metaphor.
While we can observe the miniaturization of machines since the 2000s, the true breakthrough came with the iPhone in 2007. This was a new paradigm, which significantly redefined the human-machine interface, making the primary goal that of adapting as much as possible to humans. Radical choices were made: the interface was made entirely tactile, with no physical keyboard, and it featured a high-resolution multi-touch screen, proximity sensors that turned off the screen when lifted to the user’s ear, and a display that adapted to the way the phone was held.
Machines therefore continue to become smaller, more mobile, and closer to the body, like connected watches and biofeedback devices. In the future, we can imagine having connected jewelry, clothing, and tattoos! And more importantly, our devices are becoming increasingly intelligent and adapted to our needs. Today we no longer learn how to use the machines; the machines adapt to us.
There has been a lot of talk in the media lately about vocal interfaces, which could be the next revolution in human-machine interfaces.
This technology is very interesting. A lot of progress is being made and it will become more and more useful. There is certainly a lot of work being carried out on these vocal interfaces, and more services are now available, but, for me, they will never replace the keyboard and mouse. For example, it is not suitable for word processing or digital drawing! It is great for certain, specific tasks, like telling your telephone, “find me a movie for tonight at 8 o’clock,” while walking or driving, or for warehouse workers who must give machines instructions without using their hands. Yet the interactional bandwidth, or the amount of information that can be transferred using this method, remains limited. Also, for daily use, confidentiality issues arise: do you really want to speak out loud to your smartphone in the subway or at the office?
We also hear a lot of talk about brain-machine interfaces…
This is promising technology, especially for people with severe disabilities. But it is far from being available for use by the general public, in video games for example, which require very fast interaction times. The technology is slow and restrictive. Unless people accept to have electrodes implanted into their brains, they will need to wear a net of electrodes on their heads, which will need to be calibrated to prevent them from moving, and conductive gel will need to be applied to improve their effectiveness.
A technological breakthrough could theoretically soon make applications of this technology available for the general public, but I think many other innovations will be on the market before these brain-machine interfaces.
What fields of innovation will human-machine interfaces be geared towards?
There are a lot of possibilities, a wide range of research is currently being carried out on the topic! Many projects are focusing on gestural interactions, for example, and some devices have already appeared on the market. The idea is to use 2D or 3D gestures, and different types of touch and the pressure to interact with a smartphone, computer, TV, etc. At Telecom ParisTech, for example, we have developed a prototype for a smart watch called “Watch it”, which can be controlled using a vocabulary of gestures. This allows you to interact with the device without even looking at it!
This project also allowed us to explore the possibilities of interacting with a connected watch, a small object that is difficult to control with our fingers. We thought of using the watch strap as a touch interface, to scroll through the screen of the watch. There will be ongoing development in these small, wearable objects that are so close to our bodies. For example, we could someday have connected jewelry! For example, researchers are working on interfaces projected directly onto the skin to interact with these types of small devices.
Tangible interfaces are also an important area for research. The idea is that virtually all the objects in our everyday lives could become interactive, with interactions related to their use: there would be no need to search through different menus, the object would correspond to a specific function. These objects can also change shape (shape changing interfaces). In this field of research, we have developed Versapen: an augmented, modular pen. It is composed of modules that the user can arrange to create new functions for the object, and each module can be programmed by the user. We therefore have a tangible interface that can be fully customized!
Finally, one of the major revolutions in human-machine interfaces is augmented reality. This technology is recent but is already functional. There are applications everywhere, for example in video games and assistance during maintenance operations. At Télécom ParisTech, we worked in collaboration with EDF to develop augmented reality devices. The idea is to project information onto the control panels of nuclear power plants, in order to guide employees in maintenance operations.
It is very likely that augmented reality, both virtual and mixed, will continue to develop in the coming years. The so-called GAFA companies (Google, Amazon, Facebook, Apple) invest considerable sums in this area. These technologies have already made huge leaps, and their use is becoming widespread. In my opinion, this will be one of the next key technology areas, just like big data and artificial intelligence today. And as a researcher specialized in human-machine interfaces, I feel it is important to position ourselves in this area!
Social Touch Project: conveying emotions to machines through touch
Tap, rub, stroke… Our touch gestures communicate information about our emotions and social relationships. But what if this became a way to communicate with machines? The Social Project Touch, launched in December 2017, seeks to develop a human-machine interface capable of transmitting tactile information via connected devices. Funded by the ANR and DGA, the project is supported by the LTCI laboratory at Télécom ParisTech, ISIR, the Heudyasic laboratory and i3, a CNRS mixed research unit that includes Télécom ParisTech, Mines ParisTech and École Polytechnique. “You could send touch messages to contacts, “emotitouches”, which would convey a mood, a feeling,” explains Éric Lecolinet, the project coordinator. “But it could also be used for video games! We want to develop a bracelet that can send heat, cold, puffs of air, vibration, tactile illusions, that could enable a user to communicate via touch with an avatar in a virtual reality environment.”[/box]
https://imtech-test.imt.fr/wp-content/uploads/2018/04/IHM-rognee.png9371486I'MTechI'MTech2018-04-19 14:23:572019-01-29 15:19:45Coming soon: new ways to interact with machines
Existing methods for measuring ocean surface currents are expensive, difficult to implement and limited in the amount of information they can gather. The solution proposed by the eOdyn startup, based on the algorithmic analysis of data from maritime traffic, represents a real technological breakthrough. It is very affordable and more effective, enabling the real-time and delayed observation of marine currents across the entire surface of the globe. Using this technology, eOdyn is developing many different services for the those involved in maritime transport, from the offshore oil industry, to sea rescue and research on climate change. Incubated at IMT Atlantique, the startup’s customers and partners include CMA CGM, Airbus Defence and Space, the European Space Agency and IFREMER.
Two main solutions are used to measure marine currents on the high seas. The first is to throw drifting buoys into the sea equipped with GPS and track their travel. This historical technique is still just as effective, yet it is costly and difficult to implement. It requires the buoys to be spread throughout the ocean in a homogeneous manner, and the batteries of the drifting sensors must be regularly changed. The second method is to measure the ocean currents using the six altimetry satellites that are currently in orbit. At best, when the six satellites are located above the ocean, and not above the continents, they can obtain six measurements of the water’s surface at a given time that can be used to deduce the presence and direction of the currents. This technique also requires considerable financial means, as evidenced by the €1.2 billion price tag on the next project involving the development, launch and three-year operation of the new-generation altimetric satellite known as SWOT.
The eOdyn startup now proposes a simple and inexpensive solution for the digital analysis of open data, including AIS data (Automatic Identification System), to measure the currents in real time and delayed time. This data allows ships to be operated as sensors collecting information on the currents. Considering that approximately 100,000 are sailing around the globe simultaneously, this represents 100,000 measurement points, as compared to the six points currently provided by satellites.
A simple, affordable and complete solution for observing marine currents
Each ship emits an AIS message every ten seconds. This message contains information on the vessel itself, its position and its path. All data is collected by an international network of receivers and antennas installed along the coastlines or on satellites in low Earth orbit. These AIS messages were initially designed and used as a maritime security system for preventing collisions. “It was necessary to create an open system that allows for exchanges of unencrypted information between vessels, so that they can see each other,” says Yann Guichoux, the startup’s founder.
eOdyn collects and analyzes these AIS data and submits them to an algorithm capable of analyzing each vessel’s path in different navigation conditions and produce a model of hydrodynamic behavior. Based on the vessel’s movement in relation to its planned path, it deduces the direction and intensity of the current it is affected by. “The algorithm needs a significant amount of data to function,” explains Yann Guichoux. “This is where the concepts of big data and machine learning come into play. For the algorithm, there is a learning phase for each vessel that is analyzed.”
In addition to being inexpensive, the solution proposed by eOdyn offers more comprehensive data than the altimetry satellites: “Altimetry measurement is limited, because it only obtains information on the current that is perpendicular to the satellite track” Yann Guichoux explains. “The information provided only pertains to a geostrophic current, a theoretical current. The actual current includes this geostrophic current, but also includes the tidal current and the current affected by the wind speed, which eOdyn replicates.”
Fuel economy, sea rescue and climate research
“At first, our business modelwas to sell the data we obtained. Now, we are progressively moving towards providing value-added services to various sectors,” Yann Guichoux explains. In the field of maritime transport, rather than selling the data directly to companies that do not know how to process and use them, the startup will propose optimal navigation routes that will allow ships to take advantage of driving currents and save on fuel. Furthermore, a monitoring system is being developed for offshore oil companies. It will alert the companies in real time of the presence of whirlpools that could potentially disrupt the drilling operations, cause material damage and the release pollutants into the ocean. Yann Guichoux also plans to develop a drift prediction tool for sea rescue, which will provide an estimation of the location of a person who has drifted out to sea in order to help guide search and rescue operations. Finally, the startup is also interested in providing data for research on climate change, for example to ascertain the slowdown of the Gulf Stream current.
But eOdyn won’t stop there! Using the same algorithmic basis, modified with significant variations, the startup is working on new projects for measuring swells and wind, which will come out in 2018. “A ship is a moving object in the water, subject to the constraints of the currents, swells and waves. When we look at the data and its analysis, we gain an overview of these three parameters,” Yann Guichoux explains. With the development of new tools based on the observation of these phenomena comes the promise of new fields of application waiting to be discovered.
https://imtech-test.imt.fr/wp-content/uploads/2018/04/Visuel_Une_eOdyn.jpg9801391I'MTechI'MTech2018-04-18 10:37:542018-04-18 10:37:54eOdyn: technological breakthrough in the observation of ocean surface currents