GDPR: managing consent with the blockchain?
Blockchain and GDPR: two of the most-discussed keywords in the digital sector in recent months and years. At Télécom SudParis, Maryline Laurent has decided to bring the two together. Her research focuses on using the blockchain to manage consent to personal data processing.
The GDPR has come into force at last! Six years have gone by since the European Commission first proposed reviewing the personal data protection rules. The European regulation, which came into force in April 2016, was closely studied by companies for over two years in order to ensure compliance by the 25 May 2018 deadline. Of the 99 articles that make up the GDPR, the seventh is especially important for customers and users of digital services. It specifies that any request for consent “must be presented in a manner which is clearly distinguishable from the other matters, in an intelligigble and easily accessible form, using clear and plain language.” Moreover, any company (known as a data controller) responsible for processing customers’ personal data “shall be able to demonstrate that consent was given by the data subject to the processing of their personal data.”
Although these principles seem straightforward, they introduce significant constraints for companies. Fulfilling both of these principles (transparency and accounting) is not an easy task. Maryline Laurent, a researcher at Télécom SudParis with network security expertise, is tackling this problem. As part of her work for IMT’s Personal Data Values and Policies Chair — of which she is the co-founder — she has worked on a solution based on the blockchain in a B2C environment1. The approach relies on smart contracts recorded in public blockchains such as Ethereum.
Maryline Laurent describes the beginning of the consent process that she and her team have designed between a customer and a service provider: “The customer contacts the company through and authenticated channel and receives a request from the service provider containing the elements of consent that shall be proportionate to the provided service.” Based on this request, customers can prepare a smart contract to specify information for which they agree to authorize data processing. “They then create this contract in the blockchain, which notifies the service provider of the arrival of a new consent,” continues the researcher. The company verifies that this corresponds to its expectations and signs the contract. In this way, the fact that the two parties have approved the contract is permanently recorded in a block of the chain. Once the customer has made sure that everything has been properly carried out, he may provide his data. All subsequent processing of this data will also be recorded in the blockchain by the service provider.
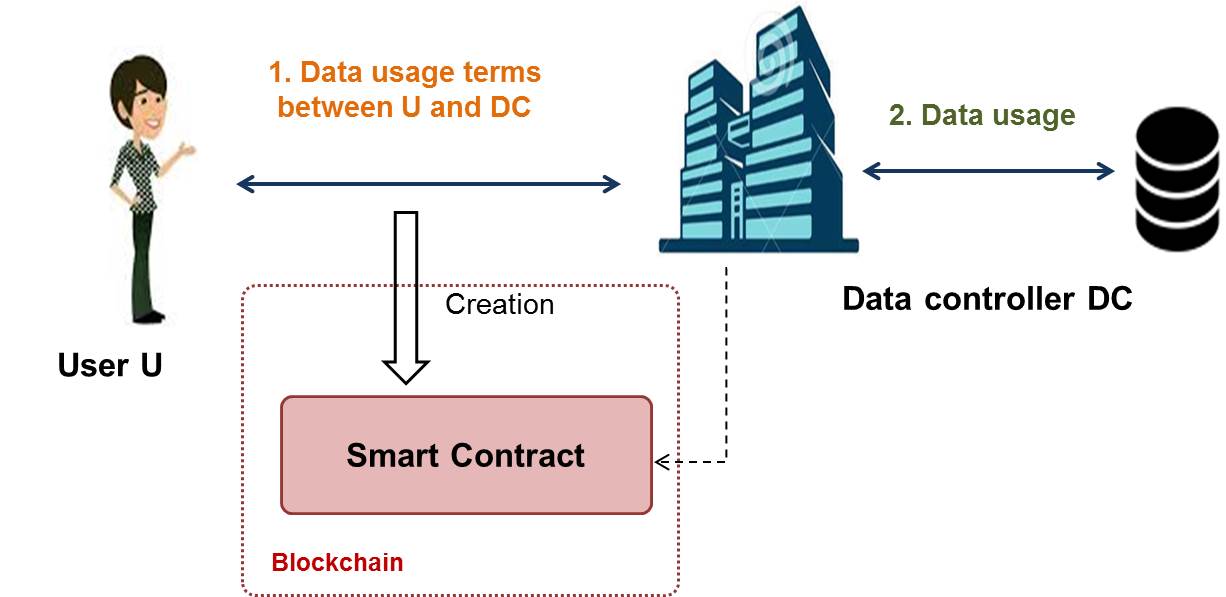
A smart contract approved by the Data Controller and User to record consent in the blockchain
A smart contract approved by the Data Controller and User to record consent in the blockchainSuch a solution allows users to understand what they have consented to. Since they write the contract themselves, they have direct control over which uses of their data they accept. The process also ensures multiple levels of security. “We have added a cryptographic dimension specific to the work we are carrying out,” explains Maryline Laurent. When the smart contract is generated, it is accompanied by some cryptographic material that makes it appear to the public as user-independent. This makes it impossible to link the customer of the service and the contract recorded in the blockchain, which protects its interests.
Furthermore, personal data is never entered directly in the blockchain. To prevent the risk of identity theft, “a hash function is applied to personal data,” says the researcher. This function calculates a fingerprint over the data that makes it impossible to trace back. This hashed data is then recorded in the register, allowing customers to monitor the processing of their data without fear of an external attack.
Facilitating audits
This solution is not only advantageous for customers. Companies also benefit from the use of consent based on the blockchain. Due to the transparency of public registers and the unalterable time-stamped registration that defines the blockchain, service providers can comply with the auditing need. Article 24 of the GDPR requires the data controller to “implement appropriate technical and organizational measures to ensure and be able to demonstrate that the processing of personal data is performed in compliance with this Regulation.” In short, companies must be able to provide proof of compliance with consent requirements for their customers.
“There are two types of audits,” explains Maryline Laurent. “A private audit is carried out by a third-party organization that decides to verify a service provider’s compliance with the GDPR.” In this case, the company can provide the organization with all the consent documents recorded in the blockchain, along with the associated operations. A public audit, on the other hand, is carried out to ensure that there is sufficient transparency for anyone to verify that everything appears to be in compliance from the outside. “For security reasons, of course, the public only has a partial view, but that is enough to detect major irregularities,” says the Télécom SudParis researcher. For example, any user may ensure that once he/she has revoked consent, no further processing is performed on the data concerned.
In the solution studied by the researchers, customers are relatively familiar with the use of the blockchain. They are not necessarily experts, but must nevertheless use software that allows them to interface with the public register. The team is already working on blockchain solutions in which customers would be less involved. “Our new work2 has been presented in San Francisco at the 2018 IEEE 11th Conference on Cloud Computing, which hold from 2 to 7 July 2018. It makes the customer peripheral to the process and instead involves two service providers in a B2B relationship,” explains Maryline Laurent. This system better fits a B2B relationship when a data controller outsources data to a data processor and enables consent transfer to the data processor. “Customers would no longer have any interaction with the blockchain, and would go through an intermediary that would take care of recording all the consent elements.”
Between applications for customers and those for companies, this work paves the way for using the blockchain for personal data protection. Although the GDPR has come into force, it will take several months for companies to become 100% compliant. Using the blockchain could therefore be a potential solution to consider. At Télécom SudParis, this work has contributed to “thinking about how the blockchain can be used in a new context, for the regulation,” and is backed up by the solution prototypes. Maryline Laurent’s goal is to continue this line of thinking by identifying how software can be used to automate the way GDPR is taken into account by companies.
1 N. Kaâniche, M. Laurent, “A blockchain-based data usage auditing architecture with enhanced privacy and availability“, The 16th IEEE International Symposium ong Network Computing and Applications, NCA 2017, ISBN: 978-1-5386-1465-5/17, Cambridge, MA USA, 30 Oct. 2017-1 Nov. 2017.
N. Kaâniche, M. Laurent, “BDUA: Blockchain-based Data Usage Auditing“, IEEE 11th Conference on Cloud Computing, San Francisco, CA, USA, 2-7 July 2018