Locked-down world, silent cities
Last spring, France decided to impose a lockdown to respond to the health crisis. Our cities came to a standstill and cars disappeared from the streets, allowing residents to rediscover quieter sounds like birdsong. A team of researchers decided to take advantage of this calm that suddenly settled over our lives to better understand the impacts of sound pollution, and created the Silent Cities project.
When the lockdown was announced and France was getting ready to come to a halt, a team of researchers launched a collaborative, interdisciplinary project: Silent Cities. The team includes Samuel Challéat,¹ Nicolas Farrugia,² Jérémy Froidevaux³ and Amandine Gasc,4 researchers in environmental geography, artificial intelligence, biology and ecology, respectively. The aim of their project is to record the sounds heard in cities around the world to study the impacts that lockdown and social distancing measures may have on noise pollution. The project also seeks to assess the effects of the variation of our activities on other animal species as our lives gradually return to normal.
Listening to cities
“We had to develop a standard protocol to obtain high-quality recordings for the analyses, but they also had to be light and easy to implement during the lockdown,” explains Nicolas Farrugia, a researcher in machine learning and deep learning at IMT Atlantique. Due to the lockdown, it was not possible to go directly into the field to carry out these acoustic surveys. A collaborative system was set up to allow a large number of participants around the world to take part in the project by making recordings from their homes. The four researchers provided a collaborative platform so that the participants could then upload their recordings.
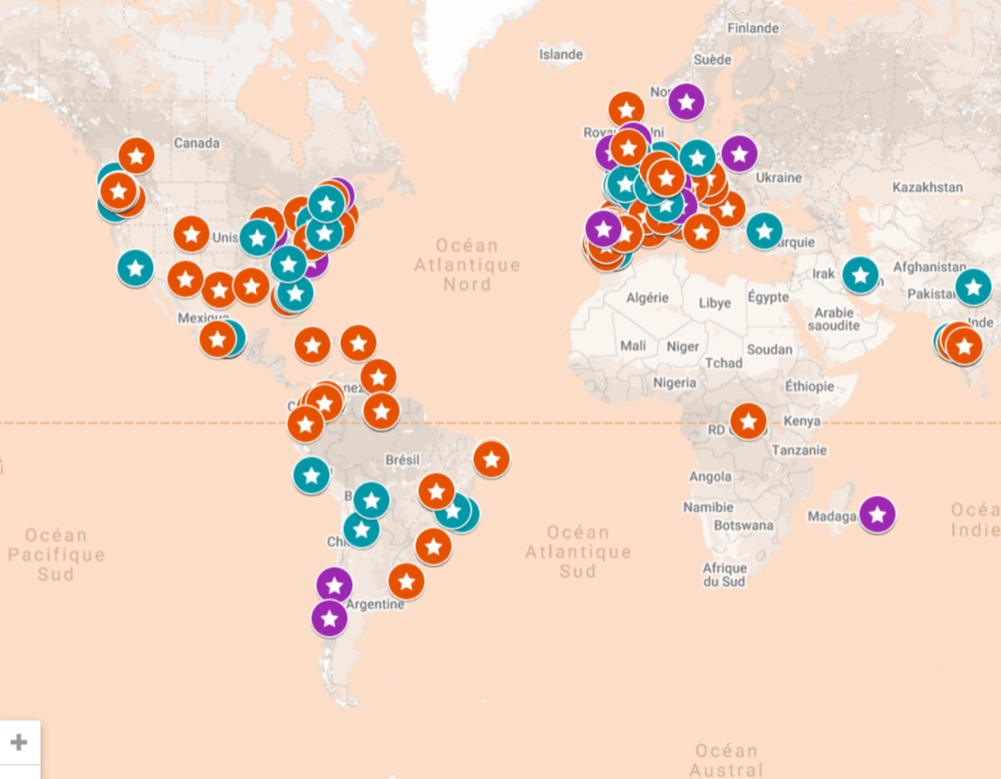
Interactive map of the Silent Cities project participants around the world.
The researchers analyzed and compared recordings at different sites using what they call ecoacoustic indices. These are mathematical values. The higher they are, the more they show the diversity and complexity of sounds in an acoustic survey. “Still using an open-access approach, we used a code base to develop an algorithm that would automatically calculate these ecoacoustic indices in order to catalogue our recordings” explains Nicolas Farrugia.
“The goal is to run audio-tagging algorithms to automatically recognize and tag different sounds heard in a recording,” he adds. This makes it possible to obtain a fairly accurate identification of sound sources, indicating, for example, the presence of a car, a raven’s caw or a discussion between several people in a sound survey.
This type of algorithm based on deep neural networks has become increasingly popular in recent years. For acoustic ecologists, they provide recognition that is relatively accurate, and more importantly, multi-targeted: the algorithm is able to seek many different sounds at the same time to tag all the acoustic surveys. “We can also use them as a filter if we want to find all the recordings where we hear a raven. That could be useful for measuring the appearance of a species, by visualizing the time, date or location,” says Nicolas Farrugia.
The contribution of artificial intelligence is also a help to estimate the frequency of different categories of sounds — for automobile traffic for example — and visualize the increase or decrease. During the lockdown, the researchers clearly observed a drop in automobile traffic and now expect to see it go back up as our lives are gradually returning to normal. What they are interested in is being able to visualize how this may disturb the behavior of other animal species.
What changes?
“Some studies have shown that in urban environments, birds can change the frequency or time of day at which they communicate, due to ambient noise,” says Nicolas Farrugia. The sound of human activities, saturating the urban environment can, for example, make it difficult for certain species to reproduce. “That said, it’s hard to talk about causality since, in normal times, we can’t listen to urban ecosystems without the contribution of human activities.” It is therefore usually difficult for eco-acoustics researchers to fully understand the biodiversity of our cities.
In this respect, the Silent Cities project provides an opportunity to directly study the variation in human activity and how it impacts ecosystems. Some of the measures put in place to respond to the health crisis could subsequently be promoted for ecological reasons. One such example is cycling, which is now being encouraged through financial assistance to repair old bicycles and creating new cycle paths. Another example is initiatives to establish staggered working hours, which would also limit the associated noise pollution. One of the possible prospects of the project is to inform discussions about how urban environments should be organized.
” Samuel Challéat, the researcher who initiated this project, works on light pollution and what we can be done to limit artificial light,” he adds. For example — like “green and blue belts,” which seek to promote the preservation of so-called “ordinary” biodiversity including in urban environments — he is currently working on an emerging planning tool, the “black belt,” which aims to restore nocturnal ecological continuity which has been harmed by artificial light. Since we know that the sounds created by human activities disturb certain ecological processes, this reasoning on ecological continuity could be transferred to the field of eco-acoustics, where the challenge would be to work to maintain or restore spaces free from any noise pollution. The data and results of the Silent Cities project could help provide insights in this area.
By Tiphaine Claveau
¹Samuel Challéat, Environmental Geography, University of Toulouse 2, CNRS, GEODE (guest researcher), Toulouse, France
²Nicolas Farrugia, Machine Learning & Deep Learning, IMT Atlantique, CNRS, Lab-STICC, Brest, France
³Jérémy Froidevaux, Conservation Biology, University of Bristol, School of Biological Sciences, Bristol, UK
4Amandine Gasc, Conservation Ecology, Aix Marseille University, Avignon University, CNRS, IRD, IMBE, Marseille, France